之前介绍的都是 Supervised Learning(监督学习算法),今天,终于开始学习 Unsupervised Learning 了。unsupervised learning 与 supervised learning 最大的区别在于,它学习所用的数据是 unlabeled training set(未经过标记的数据),即只有一系列 features,而没有 y 向量做为预期输出。 今天我们先来学习非监督学习中的第一种情况:Clustering(聚类)。所谓聚类,即将一组 input data 分成 n 簇。
K-Means Algorithm
K-means algorithm 是使用的最广泛的 clustering 算法。
它是一个迭代算法,具体来说, K-means 的处理步骤如下:
- 随机选择 K 个点(K 代表了我们希望将数据集分成 K 簇 ),这 K 个点叫做聚类中心 (cluster centroids)
- 簇分配:遍历所有的样本,依据每一个点在空间上是更接近 cluster centroids 的哪个中心,来将每个数据点分配到不同的 cluster centroids 中
- 移动 cluster centroids: 将 n 个 cluster centroids 分别移动到从属于它们的数据集的均值处
- 重复步骤 2 & 3
伪代码如下:

注意:
- 如果某个 cluster centroids 没有被分配到数据,我们通常选择直接将它删掉
- 经过一些次的迭代后,算法将会收敛
Optimization
Cost Function
和 Linear Regression Algorithm & Logistic Regression Algorithm 一样,K-Means Algorithm 也有自己的 cost function(或者叫做 distortion cost function:失真代价函数)。
 可以看出,我们在迭代求解 c & μ 的过程中,cost function 一定是在持续的下降。
可以看出,我们在迭代求解 c & μ 的过程中,cost function 一定是在持续的下降。
Choosing the Number of Clusters
具体 K 值是多少,很大程度上取决于如何看待数据,需要数据工程师对数据有一定的了解和分析,来得出 K 值。
Random Initialization Cluster Centroids
在选取聚簇中心时,建议从 training data 中随机选取 k 个数据作 cluster centroids。
随机选取的 cluster centroids 可能会造成 local optima:
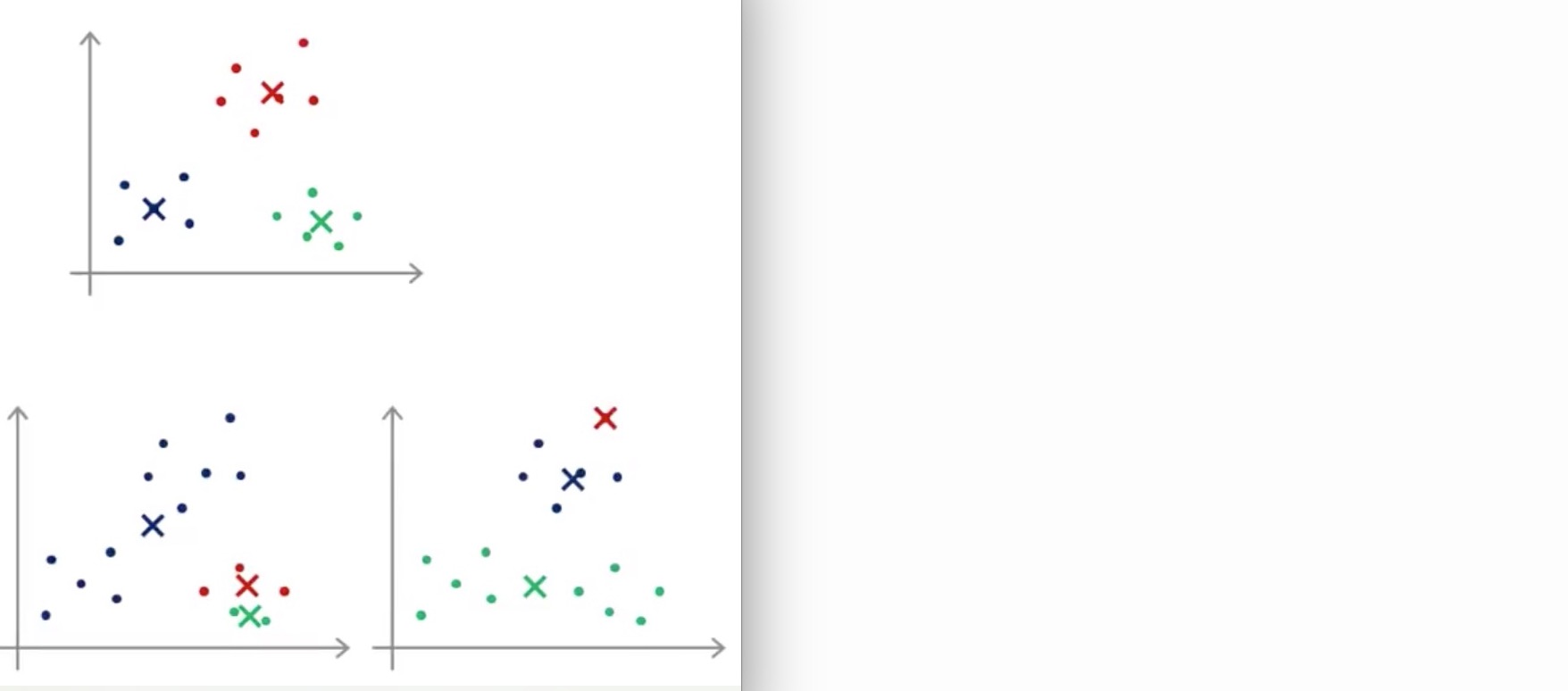
为了解决这个问题,我们可以通过多次随机初始化 cluster centroids,然后选取其中最小 cost function 的数据作为最后的结果,伪代码如下:
