上次简单聊了下推荐系统的基本概念和用户行为的一些知识,今天来聊下推荐系统中常用的算法及应用场景。
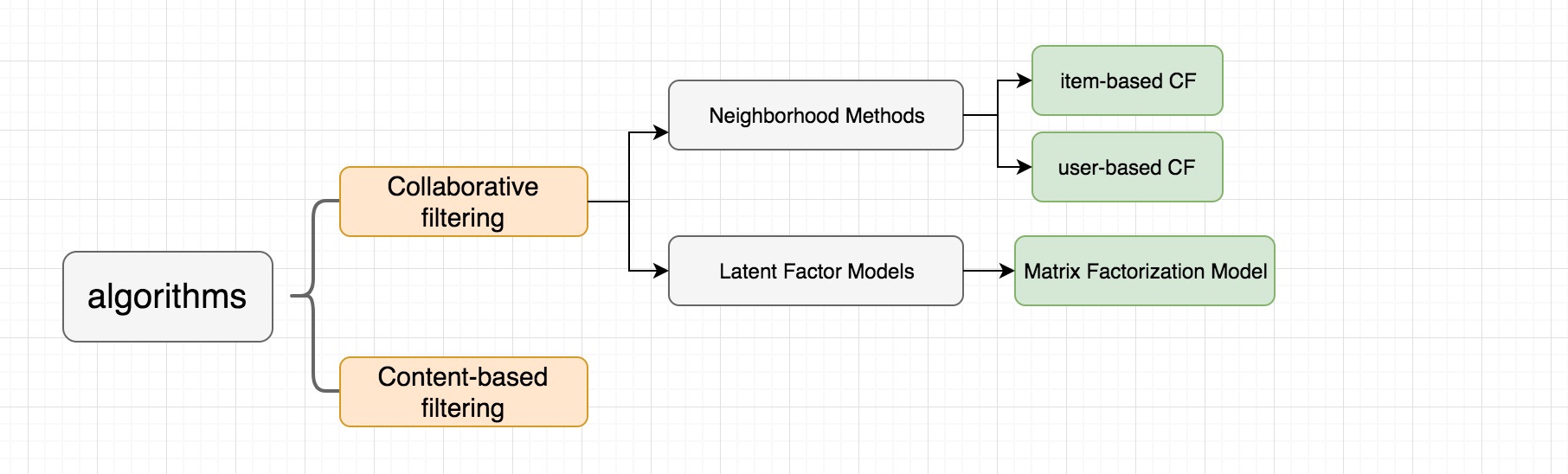 如图所示,推荐系统算法分为两大类:Content-based Filtering(基于内容的过滤) & Collaborative Filtering(协同过滤)。其中,协同过滤算是使用非常广泛的推荐系统算法,它通过收集 & 分析大量的用户行为数据来预测用户对某个内容的喜好程度。它基于这样的假设:用户将会喜欢与过去喜欢过的 items 相似的 items。
如图所示,推荐系统算法分为两大类:Content-based Filtering(基于内容的过滤) & Collaborative Filtering(协同过滤)。其中,协同过滤算是使用非常广泛的推荐系统算法,它通过收集 & 分析大量的用户行为数据来预测用户对某个内容的喜好程度。它基于这样的假设:用户将会喜欢与过去喜欢过的 items 相似的 items。
场景方面,Facebook、LinkedIn 以及一些别的社交网络公司使用协同过滤给用户推荐好友、群组等,Twitter 给用户推荐 follow 人选等,Amazon、Netflix、 Youtube 给用户推荐一些用户可能感兴趣的物品。
具体来说,协同过滤又分为两种类型:Neighborhood-Based CF(基于领域的方法)、Latent Factor Models(隐语义模型)。由于所涉及到的知识点很多,我们先来了解下协同过滤分支的 Neighborhood-Based CF 算法。
基于领域的方法包含 User-based CF(基于用户的协同过滤) & Item-based CF(基于物品的协同过滤)
User-based CF
基于用户的协同过滤算法:给用户推荐和他兴趣相似的其他用户喜欢的物品。它是推荐系统中最古老的算法,当然现在在大部分场景中已经被 Item-based CF / Latent Factor Models 算法替代了。具体来说,该算法包含两步:
- 找出和目标用户有最多相似兴趣度的用户集合
- 找出该集合中的用户喜欢的,但是目标用户没听过的物品,按照优先级推荐给目标用户
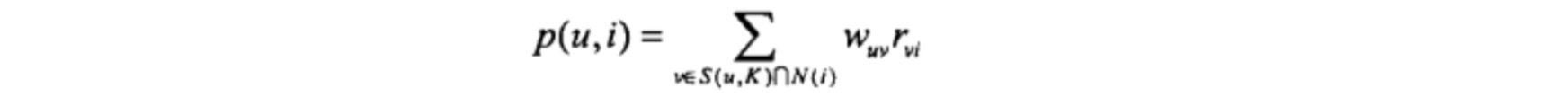 上图是 User-based CF 的一个简单公式,其中 p(u,i) 即预测用户 u 对 物品 i 的喜好程度,Wuv 表示用户 u 和用户 v 的相似度,rvi 表示用户 v 对物品 i 的喜好程度。
上图是 User-based CF 的一个简单公式,其中 p(u,i) 即预测用户 u 对 物品 i 的喜好程度,Wuv 表示用户 u 和用户 v 的相似度,rvi 表示用户 v 对物品 i 的喜好程度。
这里提到一个相似度的问题,数学上有很多种方式计算相似度,包括欧式距离、皮尔逊相关系数、余弦相似度、Jaccard相关系数、汉明距离甚至 TF-IDF 等等等等,不同的场景使用不同的相似度算法,这里就先不一一展开了(以后可能会专门写篇博客谈这个问题吧。。。)。简单来说,用户相似度取决于两个用户同时对多少物品有过行为。
Item-based CF
基于物品的协同过滤算法:给用户推荐和他之前喜欢的物品相似的物品。它也是目前用的非常广泛的算法,和 User-based CF 类似,该算法也主要分为两步:
- 计算物品之间的相似度
- 根据物品的相似度和用户历史行为给用户生成推荐列表
物品相似度取决于两个物品被多少 users 有过行为(而不是通过物品本身的内容属性,如:标题、出版社等具体的 features)。譬如《Doing Data Science》和《High Performance Spark》的相似度比《The VIENAM WAR》的高,因为有更多的人同时买过《Doing Data Science》&《High Performance Spark》。
使用 Item-based CF 最典型的例子是 Amazon:

Algorithm
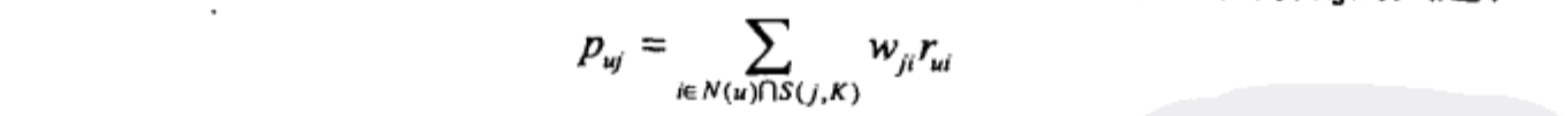 其中 :
其中 :
- puj 表示 user-u 对 item-j 的喜好程度
- wij 表示 item-i 和 item-j 的相似度
- rui 表示 user-u 对 item-i 的喜好程度(既有数据)
Evolution of the algorithm
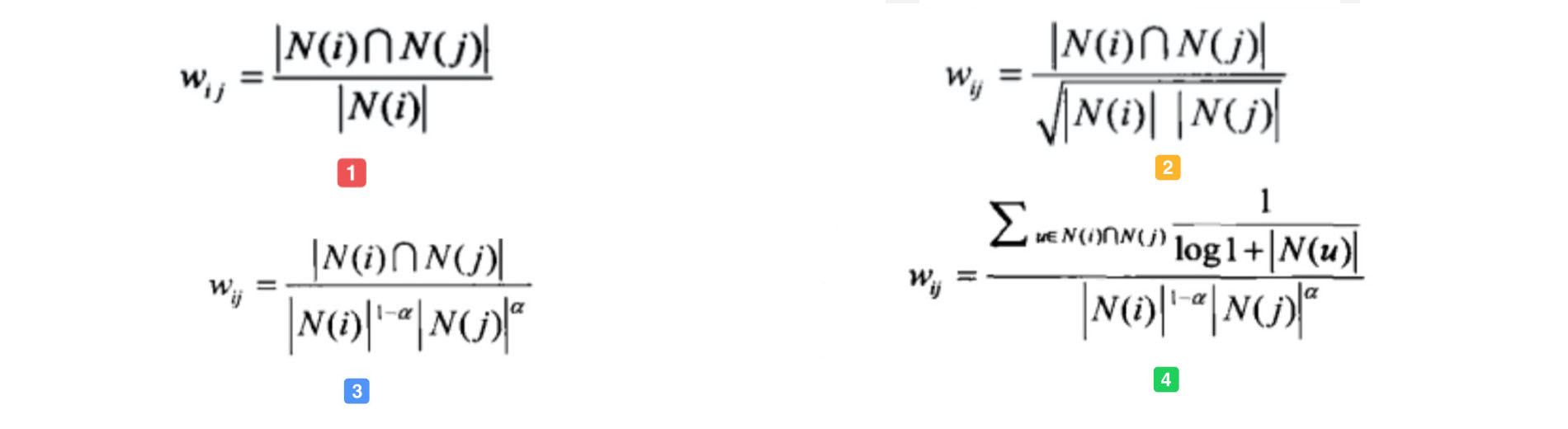
基础算法
图1为最简单的计算物品相关度的公式,分子为同时喜好 item-i & item-j 的用户数。
对热门物品惩罚
但是图1存在一个问题,如果 item-j 是很热门的商品,导致很多喜欢 item-i 的用户都喜欢 item-j,这时 wij 就会非常大。同样,几乎所有的物品都和 item-j 的相关度非常高,这显然是不合理的。图2中分母通过引入 N(j) 来对 item-j 的热度进行惩罚。
对热门物品进一步惩罚
如果 item-j 极度热门,上面的算法还是不够的。举个例子,《Harry Potter》非常火,买任何一本书的人都会购买它,即使通过图2的方法对它进行了惩罚,但是《Harry Potter》仍然会获得很高的相似度。这就是推荐系统领域著名的 Harry Potter Problem。如果需要进一步对热门物品惩罚,可以继续修改公式为如图3所示,通过调节参数 α,α 越大,惩罚力度越大,热门物品的相似度越低,整体结果的平均热门程度越低。
对活跃用户惩罚
同样的,Item-based CF 也需要考虑活跃用户(即一个活跃用户(专门做刷单)可能买了非常多的物品)的影响,活跃用户对物品相似度的贡献应该小于不活跃用户。图4为集合了该权重的算法。
Comparison
可以看出,User-based CF 和 Item-based CF 思想其实有很多相似的地方,不同之处在于,User-based CF 是基于用户和用户之间的相似度来推荐,而 Item-based CF 是基于物品和物品之间的相似度来推荐。
User-based CF 需要维护一个 user-user 的相似度矩阵,所以当用户增长很快/用户量很大的时候,维护 user-user 矩阵的代价就很大。 Item-based CF 需要维护一个 item-item 的相似度矩阵,当物品数量增长很快/物品量很大的时候,维护 item-item 矩阵的代价就很大。
所以视不同的场景,我们需要用不同的算法来实现。对于新闻类网站,物品的增长速度很快,那么实时维护 item-item 矩阵就变得很不实际,这时可以考虑使用 User-based CF。说白了,哪种算法的维护成本低就选用哪种。
但是现今互联网中,一般应用的 user 数量和 item 数量都会比较大,导致相似度矩阵的计算和维护成本高昂,研究员们又提出了一种新的算法 Latent Factor Models. 我们下周再来聊这种算法。