Partition
分片是指将大的数据集按一定规则拆分成小的数据集,来降低数据量增长过大时带来的问题。方式大体来说有两种:哈希分布 & 顺序分布。很多时候要根据具体业务选择分片方式。 Partition 的好处:
- improves performance(write): by limiting the amount of data to be examined and by locating related data in the same partition
- improves availability: by allowing partitions to fail independently, increasing the number of nodes that need to fail before availability is sacrificed
需要解决的问题:
- 自动负载均衡。分布式存储系统需要自动识别负载高的节点,当某台机器的负载高时,自动将其上的部分数据迁移到其他机器。
- 一致性:分片后数据可能分布在不同存储服务器上,无法使用数据库自带的单机事务,需通过分布式应用事务一致性模型来解决
Hash partitioning(哈希分区)
判定 hash 算法的四个指标:
- 平衡性(Balance): 是指 Hash 的结果能够尽可能分布均匀,充分利用所有缓存空间。
- 单调性(Monotonicity): 是指如果已经有一些内容通过哈希到了相应的缓冲,又有新的缓冲加入到系统中。要能保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
- 分散性(Spread): 分布式环境中,不同终端通过 Hash 过程将内容映射至缓存上时,因可见缓存不同,Hash 结果不一致,相同的内容被映射至不同的缓冲区。
- 负载(Load): 是对分散性要求的另一个纬度。既然不同的终端可以将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。
Hashing
一般是通过数据的某个特征计算哈希值,并将哈希值与集群中的服务器建立映射关系,从而将不同数据分布到不同服务器上。
hash(object) % N
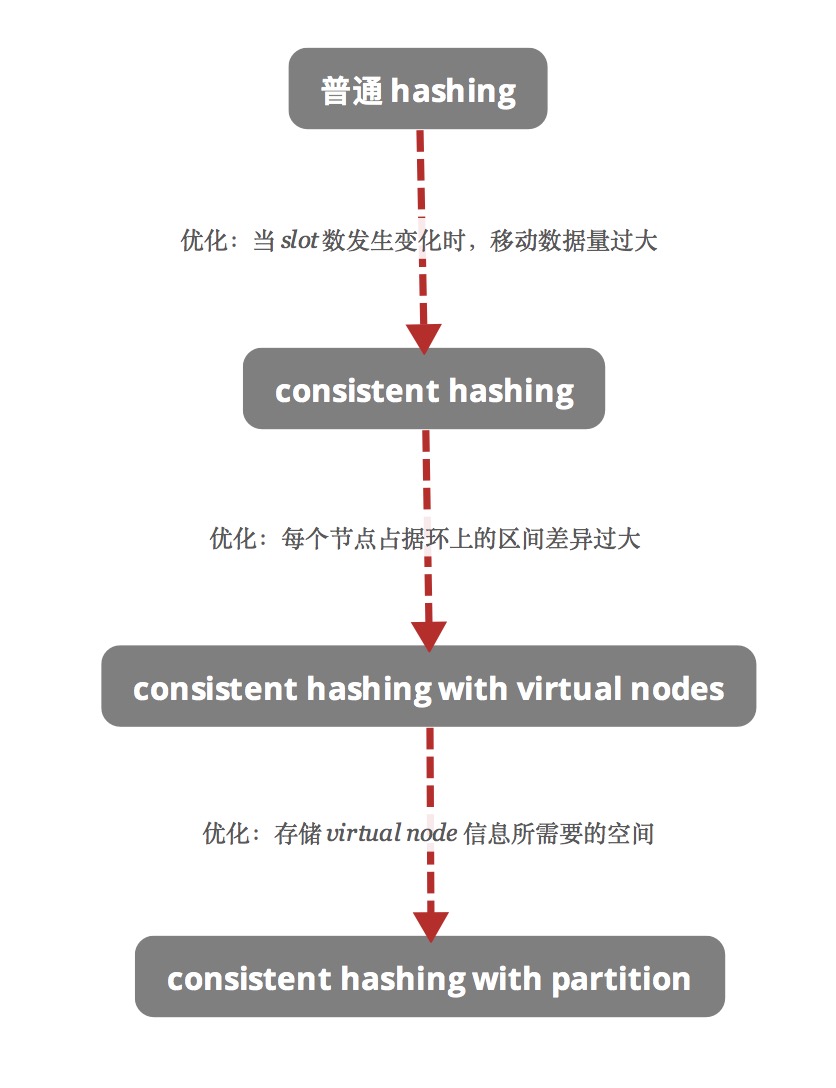
Consistent hashing
目标:当 slot 数发生变化时,尽量少的移动数据
存在的问题:每个节点占据环上的区间可能差异很大
Consistent hashing with virtual nodes
目标:优化减少每个节点占据环上的区间的差异
注意:
- 预设合理的虚结点数:如果改变虚节点数,就需要重新分配所有的数据项,将导致大量的数据移动
- 存储 virtual node 信息所需要的空间可能很大
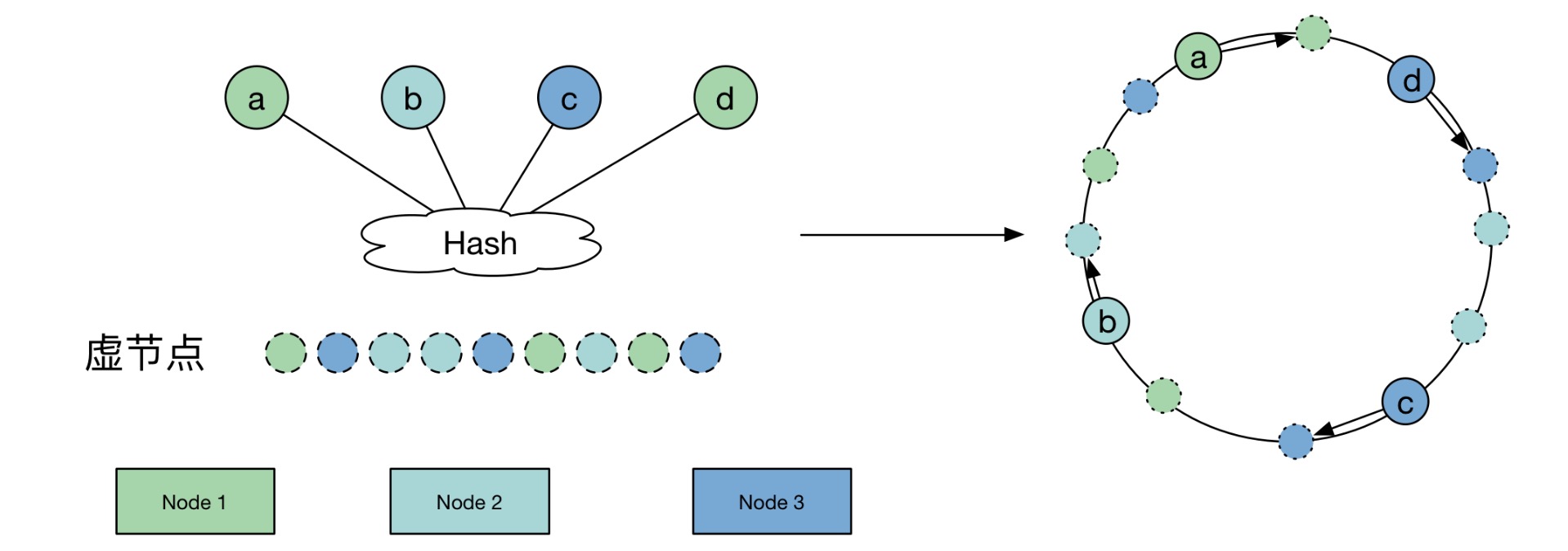 通过 virtual node 将哈希环分割成更小的粒度,小粒度的 hash 块被不同的 node 持有。
通过 virtual node 将哈希环分割成更小的粒度,小粒度的 hash 块被不同的 node 持有。
Consistent hashing with partition
目标:通过 bit 位来映射 Nodes,节省空间 partition 与 virtual nodes 其实是一个概念
References
Ring实现原理剖析 一致性哈希算法的理解与实践 Partition Ring vs. Hash Ring
Sequential partitioning(顺序分区)
哈希分布破坏了数据的有序性,只支持随机读数据,不支持顺序读。但某种程度上,我们可以在系统层面做优化,如按用户来进行数据拆分,保证同一用户的数据都落在同一节点上,这样就可以对同一用户的数据进行顺序扫描。 但这种做法也可能有问题,如某些用户的数据量很大,而其他用户量小时,数据分布就不均衡了。
这时,可以采用顺序分布的方式,将大表按一定顺序划分为连续的子表,然后将子表按一定策略分配到存储节点上。 需要使用索引(多层索引)来记录子表信息,与 B+ tree 数据结构很类似。 需要考虑子表的分裂与合并。
总结
| 分区方式 | 特点 | 代表产品|
| ———- | — | — |
| Hash partitioning | 1. 离散性好
2. 无法顺序读取 | Redis Cluster
Cassandra
Dynamo |
| Sequential partitioning | 1. 离散性不好
2. 可顺序读取 | Bigtable
HBase
Hypertable |