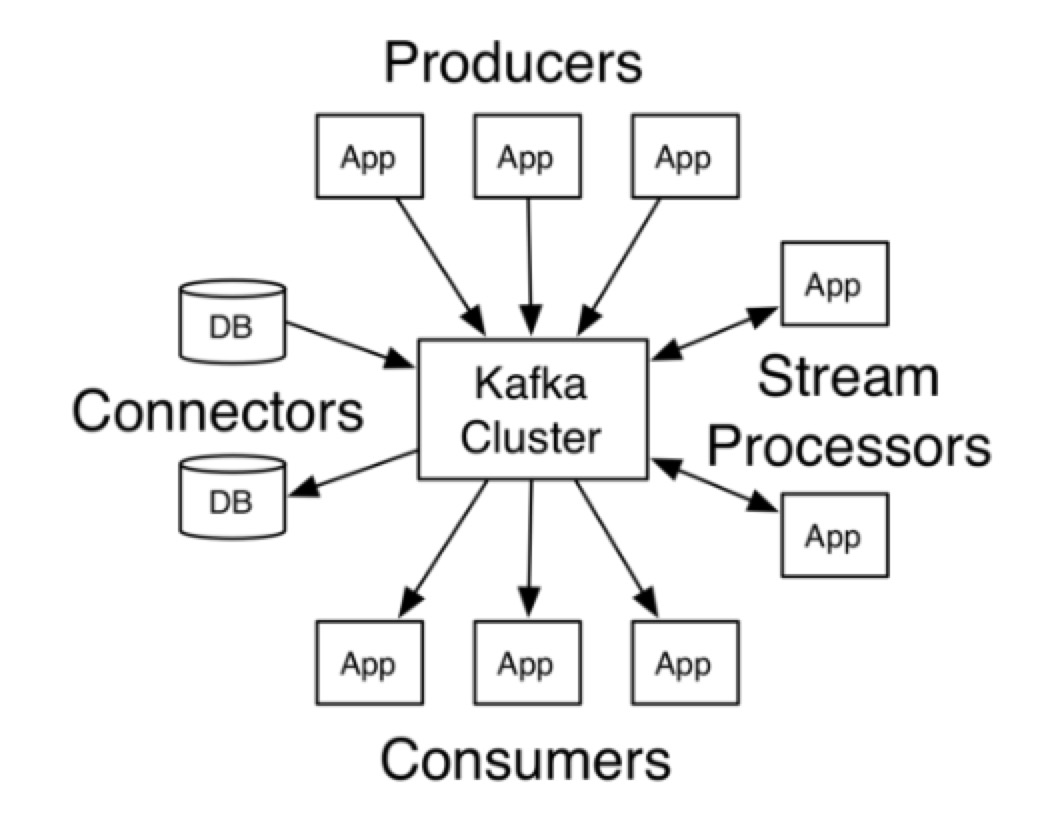
What’s kafka
- Kafka 可以提供 MQ 功能:发布 & 订阅消息
- Kafka 可以提供 stream processing 功能
- Kafka 提供对 messages/ streams 的存储功能(通过配置,决定存储的 retention,当然,本质上我们不能把 Kafka 当成真正的存储系统来用)
- Kafka 是 distributed system,搭建 cluster 来灵活动态的伸缩容
Kafka vs Messaging system
Kafka 是一个 MQ 系统,支持 publish & subscribe messages,就像 ActiveMQ, RabbitMQ,核心就是处理消息,提供 producer & consumer 的解耦。 Kafka 和普通 MQ 系统的真正不同在于它的 stream processing capabilities,可以通过该功能读取 streams & 动态的输出 streams。
Kafka vs RabbitMQ
- RabbitMQ 不会存数据,没有消费者的话,msg 就丢了
- RabbitMQ 支持灵活的 exchange 策略,Kafka 的 topic 不支持
- Kafka 需要 Zookeeper 来管理 cluster,RabbitMQ 不需要
- Kafka 对 Java 友好
- Kafka 的社区活跃度比 RabbitMQ 高
Kafka vs Big data systems
Hadoop 支持大规模的 data 存储 & 周期性的处理文件数据。 Kafka 侧重于提供实时、低延迟的大量 data 处理能力
Kafka vs ETL tools
ETL 的主要能力在于:从一个系统中获取到数据,插入到新的系统中。Kafka 也可以提供该能力。
Summary
Kafka 通过抽象数据流的概念,把以上三种类型系统的能力结合了起来。而 stream processing 正是 Kafka 的突出亮点。
Messages and Batches
Messages
kafka 中 message 是可以持久化一定时间的,但是不同的配置 (retention)会影响 messages 保留的时间长短。触发阈值时,消息会被删除。
retention 是针对 topic 来配置的,可以配置的项有两个:
- log.retention.ms: Retention by time is performed by examining the last modified time (mtime) on each log segment file on disk.
- log.retention.bytes: all retention is performed for an individual partition, not the topic. If you have specified a value for both log.retention.bytes and log.retention.ms (or another parameter for retention by time), messages may be removed when either criteria is met.
不同的业务场景对 message 丢失、重复、延迟的忍耐程度不同,需要使用不同的配置参数、不同的 API
Batches
Batches 是一组 messages。Batches 中的 messages 拥有相同的 topic and partition。 producer client 创建消息后,实际上会先缓存在本地的 buffer 中,等收集到一定量后,batches 发送给 broker。这种方式提升了效率,但导致了消息发送的延迟。可以根据业务需求,通过配置 batch 的 size 来调节延迟。
Serializer and deserializer
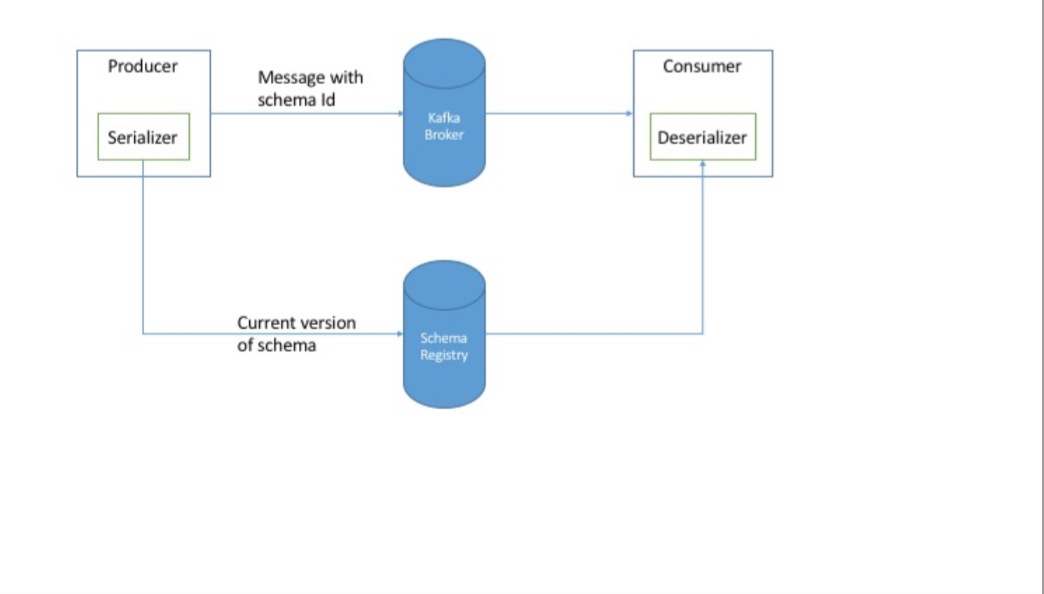
message 在网络间传递时,是需要 serialize 的,这时就需要有 serializer。
kafka 中有以下几种 serializer:
- string serializer
- Custom Serializer
- Serializing Using Apache Avro
默认的 string serializer 不够灵活,custom serializer 又需要投入大量的时间开发,比较建议使用现成的 serializer 工具,如 Apache Avro。Avro 通过 schema 的概念很好的实现了 serialize & deserialize 的功能。schemas 存储在独立的 register 中。producer & consumer 都从 schema repository 中读取 schema 来达到自动更新两端的能力。
Topic
kafka 中的消息是按 topic 来组织的。可以把 topic 理解成数据库中 table 的概念。
Partitions
partition 是 topic scale 的重要手段,它跟存储系统中的分片是一个概念。topic split 成多个 partitions,topic 中的 messages 分布到不同的 partitions 中,平衡负载,提高写性能,同时通过增加 consumer group 中 consumers 的个数,达到提高读性能的目的。
kafka 可以保证单个 partition 上的 msg 是有序的,但是在各个 partition 间,是无法维持一个全局有序的。
如何决定消息落到哪个 partition 上:
- 不指定 message 的 partition & key 参数,根据 round-robin algorithm ,随机落到某个 partition
- 指定 message 的 key 2.1 默认的 partitioner 对 key 应用一定的 hash 算法,来决定 partition 位置 2.2 默认的 key partition 算法在某种业务场景下,会导致各个 partition 的数据量严重不平衡。根据业务场景自定义 partitioner,对 key 应用自定义的算法来分配 partition 位置
- 指定 partition,则忽略 key,直接按照配置的 partition 去存储消息
改变 topic 的 partition 个数后,相同 key 的 messages 在改变前后可能分配到不同的 partition 中,如果业务系统对此敏感,则建议: 1、初始时,估算好恰当的、足够大的 partitions 2、初始化后,尽量不改
为了更好的做负载均衡,Kafka 尽量将所有的 Partition 均匀分配到整个集群上。一个典型的部署方式是一个 Topic 的 Partition 数量大于 Broker 的数量。同时为了提高 Kafka 的容错能力,也需要将同一个 Partition 的 Replica 尽量分散到不同的机器。
Producer
Producers 负责生产消息。 消息成功写到 topic 后,broker 会返回 producer 消息的 topic, partition & the offset of the record within the partition。
Send
发送方式有两种:
- Synchronous send
- Asynchronous send
Retry
消息可能因为一些异常原因写失败,异常分为两类:
- Retriable errors: KafkaProducer 针对这种异常,可以自动的发起重试。全部逻辑隐藏在 send 方法中,开发人员不需要人工干预
- a connection error can be resolved because the connection may get reestablished.
- A “no leader” error can be resolved when a new leader is elected for the partition.
- Nonretriable errors: 这种错误没法通过重试修复,会直接抛异常,需要开发人员处理
- message size too large error
Acks
acks 参数控制 producer 认为 message 写成功之前必须接收到 partition 成功写入的副本数(针对 replicas)。可以把acks 理解为用来控制数据备份时的一致性强弱的。
当配置 acks 为:
- 0: producer 不会等待 broker 的写成功回复,producer 发完 request 直接 return,把操作权交给 application developer,这种配置可能造成消息丢失
- 1: leader replica 成功写消息后,broker 响应写成功通知 如果 partition leader 所在的 broker crash 了,而新的 leader 还没有选举出来,则 producer 会收到 error 的 response 并发起 retry。 如果 partition leader 写成功(响应 producer 成功)后 crash 了,而一个还没有同步到 message 的 replica 被选为新的 leader,那这条消息就丢失了。
- all: request 将存在 buffer 中,直到 leader 观察到所有的 follower replicas 都备份完 messages,才响应 producer。优点:数据一致性强;缺点:性能差。
Brokers and Clusters
一个 Kafka 的服务器叫做一个 broker。broker 接受 producer 传递过来的 messages,store messages 到指定的 partition 中,并分配 offsets。它还接受 consumer 发过来的 poll messages request & heartbeats request
broker 的 metadata 在 zookeeper 中维护。每一个 broker 都配置有自身唯一的 id,当 broker start 时,broker 将自身的 id 注册到 zk 中(通过写一个 ephemeral node, 临时节点),如果已经存在一个相同 ID 的 ephemeral node,zk 会返回错误。
当 broker 和 zk 断掉连接后(broker stop / network partition / long garbage-collection pause),broker 启动时创建的 ephemeral node 将自动被 zk 删除。
当完全丢失 broker & 删除对应的 ephemeral node 后,重启一个具有相同 id 的新 broker,该 broker 将替代丢失的旧 broker,接受原 broker 相同的 partitions & topics。
ephemeral node 临时节点是 zookeeper 中的概念 A znode can be either persistent or ephemeral. A persistent znode /path can be deleted only through a call to delete. An ephemeral znode, in contrast, is deleted if the client that created it crashes or simply closes its connection to ZooKeeper.
The Controller
一组 brokers 可以搭建成一个 cluster。在 cluster 中有一个 broker 担任 cluster controller,一般是第一个加入 cluster 的 broker 担任 controller,它会在 zk 中创建一个名叫 /controller 的 ephemeral node。 其他后加入 cluster 的 brokers 也试图创建 /controller ephemeral node,但是失败(因为已经有别的 broker 创建成功),其余的 brokers 会监听 /controller node。当 controller broker stop or loses connectivity to zk 时,它创建的 /controller node 会被 zk 删除。cluster 中别的 brokers 将被 zk 通知 controller 丢失,剩下的 brokers 继续抢占 /controller node,第一个写成功的成为新的 controller。
上面提到的内容都是 kafka 作为 application 使用 zk 暴露的 ephemeral node 功能,来自己实现 master election broker controller 和 partition leader 不是一个概念。
controller broker 除了承担普通的 broker 功能外,还负责 partition leaders 的选举。如果 controller broker 发现有别的 broker 离开 cluster(通过监听 zk 的相关路径 node)时,那么所有存在于丢失 broker 上的 leader partitions 需要新的 leader,controller 负责选择一个 partition 作为 leader,并通知给各个 brokers partitions。新的 partition leaders 明确自己的职责,followers 则明确自己需要同步的 new leader。
Multiple Clusters
The replication mechanisms within the Kafka clusters are designed only to work within a single cluster, not between multiple clusters.
The Kafka project includes a tool called MirrorMaker, used for this purpose.
Zookeeper
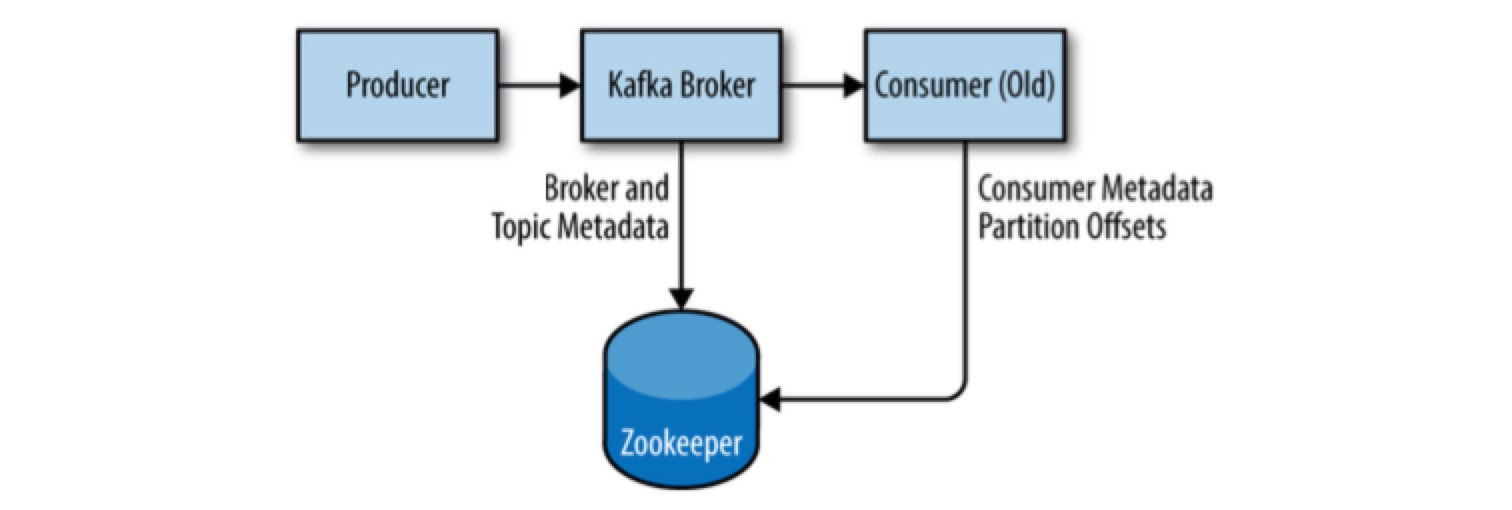 Kafka 用 Zookeeper 来维护 broker cluster,存储 brokers, topics, partitions 的 metadata。
Consumer 的 metadata 在 kafka v0.9 之前的版本中,是通过 Zookeeper 维护。但是在 v0.9 之后,可以选择通过 zookeeper 管理,也可以选择通过 kafka brokers 管理,因为频繁的读写 offsets 对 zk 的压力较大,所以推荐通过 Kafka broker 管理。
Kafka 用 Zookeeper 来维护 broker cluster,存储 brokers, topics, partitions 的 metadata。
Consumer 的 metadata 在 kafka v0.9 之前的版本中,是通过 Zookeeper 维护。但是在 v0.9 之后,可以选择通过 zookeeper 管理,也可以选择通过 kafka brokers 管理,因为频繁的读写 offsets 对 zk 的压力较大,所以推荐通过 Kafka broker 管理。
Replication
前面我们介绍了 Kafka 的 topic partition,现在来了解下 replication。
为了实现系统的可靠性(availability) & 耐用性(durability),我们可以对 partition 做 replicated。kafka 中的 data 按 topics 组织,每个 topic 可以做 partition,每个 partition 可以有多个 replicas。
partition replicas 有两种角色:
- leader: 每个 partition 有一个 leader
- 负责该 partition 的所有读写操作(producer, follower replicas, consumer),这也是保持 consistency 的一种方式
- leader 还知道每个 followers 的同步进度
- follower: followers 不直接承担 client 的读写任务。它们的唯一工作就是通过向 leader 发 fetch request 备份 messages。
consumer.poll / replica fetch messages 时,会把自身已有的最大 offset 带给 leader 来获得准确的 messages。当 partition leader crashes 时,其中一个拥有最多消息(最大 offsets)的 followers 将变成 leader。
replication 采取的是 follower fetch(poll) data
Consumer
consumers 消费消息。同时 consumer 会跟踪上报自己已消费消息的 offset(kafka 的每个消息在 topic 的 partition 中都有一个唯一的 offset)。 consumers 是以 consumer group 的形式工作的。group 保证每个 partition 只能被一个 consumer 消费,换言之,group 中的 consumer 消费互不相同的 partition。 一个 consumer group/ consumers 可以(通过正则表达式)订阅多个 topics,当新增满足正则表达式的 topic 时,能自动读取到该 topic 的 msg 。
Consumer Groups
consumer groups 的可能组织结构有:
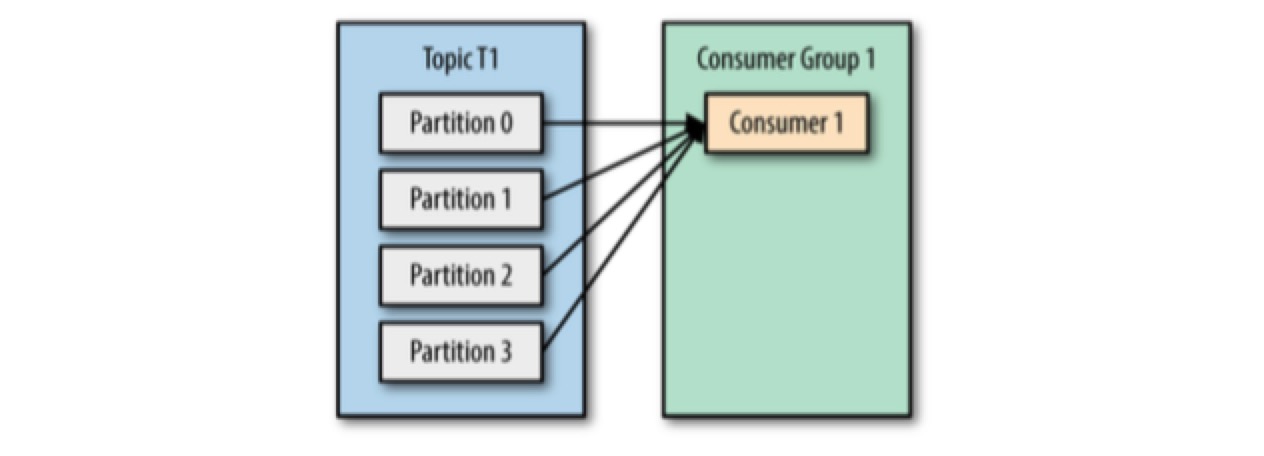
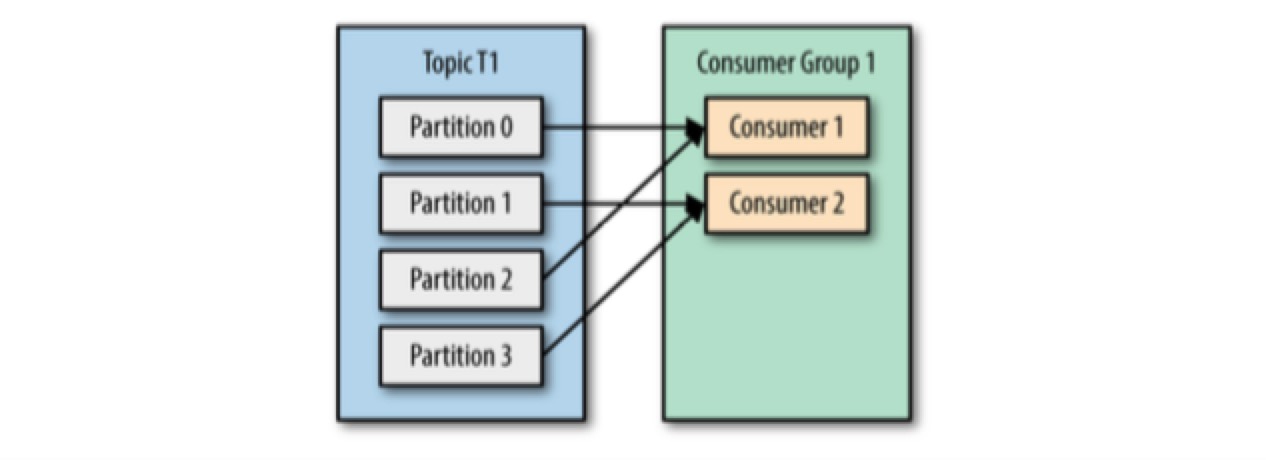
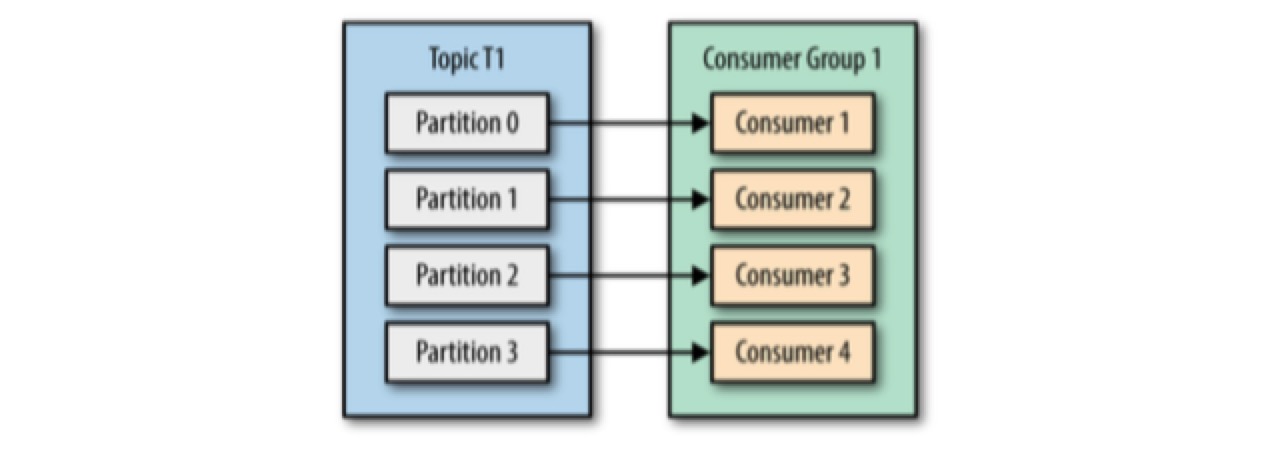
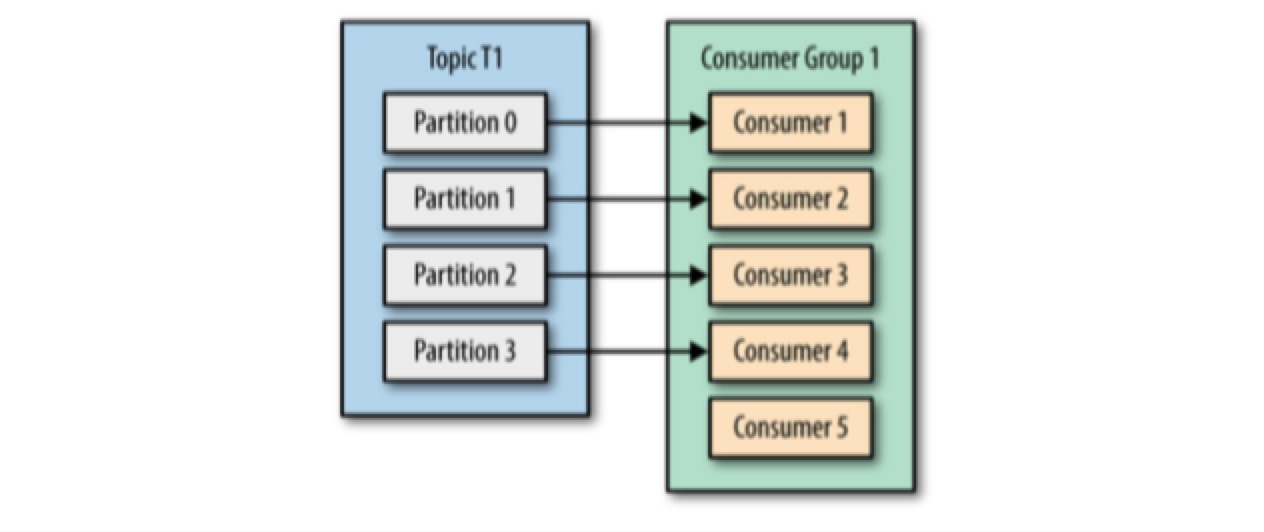
由于 consumer 经常会做一些高延迟的操作,例如写数据库、分析数据等,consumer 的消费能力可能会小于 producer 的生成能力。
分析以下场景:
- 如果 partition count > consumer count,可以往 consumer group 中加更多的 consumers 来分担负载,提升消费能力
- 如果 partition count < consumer count,多出来的 consumers 会闲置,需要增加 partition 的数量。但是这带来的问题是:相同 key 的 messages 在增减 partition count 前后可能分配到不同的 partition 中 所以,为 topic 创建 partitions 时要预留足够的个数。这样当将来负载变大时,可以方便的通过添加 consumers 来分流。
上面我们提到的都是一个 consumer group 对 topic 的消费。很多情况下,同一个 topic 的消息会有多个不同的应用(user cases)感兴趣(每一个 use case 都能拿到该 topic 的所有 messages),这时就需要为不同的 user case 创建不同的 consumer group,即有多个 consumer groups 消费同一个 topic。
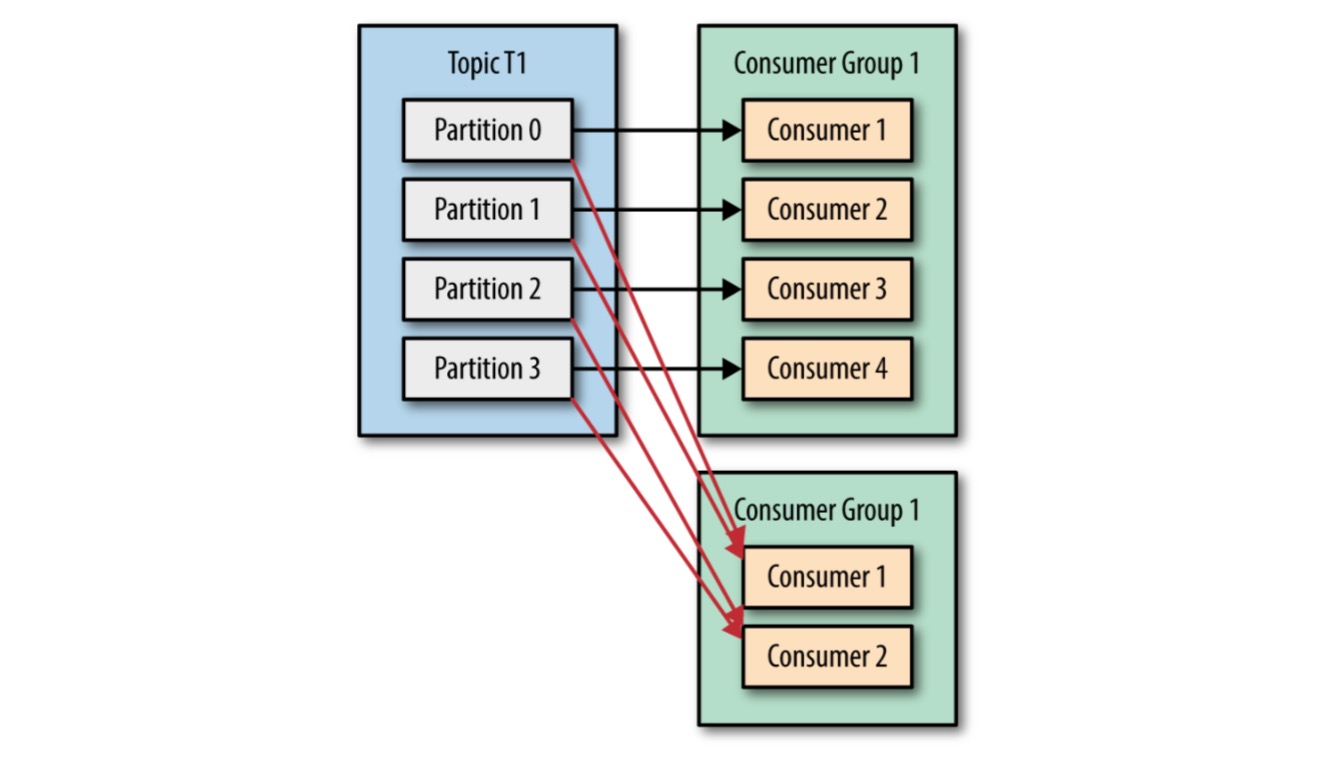
Partition Rebalance
发生一下情况时,需要对 consumer group 进行 partition rebalance:
- 当 consumer group 的消费能力不足时,增加 consumer
- 当 consumer crash /network failure 时,移除 consumer
- 管理员增加新的 partition
通过对 partition rebalance 的支持,Kafka 具备了 high availability & scalability。但是正常情况下,尽量避免 partition rebalance。因为:
- consumer 不能消费消息,consumer group 会有一个短暂的不可用期
- 当 partition 从原先的 consumer 移到新的 consumer 时,原先 consumer 丢失了它当前处理的状态
设计阶段,就要把由于 rebalance 引发的潜在的消息重复处理的情况考虑进去。
Consumer Group coordinator & Consumer Group leader
关于 consumers 的维护,有两个重要的概念:group coordinator & group leader:
- group coordinator: 是特殊的 broker。consumers poll 消息 & commit 消费消息记录时,会发送 heartbeats 到 group coordinator 来同时告知自己的健康状况。
- group leader: 第一个加入 consumer group 的 consumer 就是该 group 的 group leader。group coordinator 会把 consumers 列表发给 consumer group leader 来维护。group leader 负责为 consumer assign & reassign partitions。
如果 consumer crashed/network failure,长时间没有发送 heartbeats 到 group coordinator 时,group coordinator 会认为该 consumer 失联,并通知 group leader rebalance partition,group leader 将 rebalance 的结果通知 group coordinator,由 group coordinator 来通知 consumers 新的 partitions 关系。
Poll loop
consumer 中的核心功能几乎都在 consumer.poll() 方法中。poll(timeout) 通过 timeout 参数控制 poll 的阻塞等待数据时间。如果 timeout = 0,则立即返回,无论是否有新消息。timeout 的值是需要根据自身业务设置的。但是它不仅仅是从 broker 中读取消息:
- 初始调用 poll() 时,会去找 groupCoordinator & 加入 consumer group & 接收 partition assignment
- poll 内部负责处理 partition rebalance
- 发送 heartbeat: 当 consumer 停止 poll() 时,会停止发 heartbeat,被 group coordinator 认为 fail,把分配给它的 partitions 分配给 consumer group 中别的 consumer。
所以:
- consumer 需要持续 poll 数据
- consumer 处理数据的过程要越快越好,避免由于长时间不发 heartbeat,引起宕机误判
Commits and Offsets
Kafka 不像大多数 JMS queue 那样,broker 不主动跟踪 consumer 的 ack,而是通过 consumer 发起 commit 来更新最新的 offset 到 _consumer_offsets topic 中
consumer.poll()时, broker 会返回还没有消费的消息记录,消息中带有自身的 offset。 consumer 通过 commit 动作发送一个带有 partition offset 的 message 到 kafka broker 的特殊 topic(__consumer_offsets topic) 来更新 offset。
consumer 什么时候 commit 该消息呢?
Automatic Commit
配置 enable.auto.commit=true,consumer 会每隔一个 interval (默认每隔5s)自动提交 consumer 通过 poll() 收到的最大的 offset。 automatic commits 也是通过 poll loop 来实现的。每次 poll, consumer 都会自动检查是否到时间执行一次 commit 来提交最近一次 poll() 获得的最大的 offsets。
当 consumer crashes / new consumer 加入 consumer group,会触发 rebalance。在 rebalance 后,每个 consumer 被分配一组新的 partitions,并获取到最新的 committed offset of each partition 来继续工作。 但是考虑以下情况:假设配置每隔 5s commit the latest offset,上次提交 2s 后,发生了 rebalance,所有 consumers 获取到之前最近的 offsets,但这个 offset 其实是 2s 前的,这 2s 间到达 consumers 的消息将会被处理两次。 可以配置较小的 interval 来减少重复消费的消息,但是本质上无法完全避免。
可以看出,操作 committed offset 的位置,是可能发生以下情况:
- 重复读取 & 消费消息
- 遗漏处理消息
Commit Current Offset
如果想对 offset 的控制更准确,配置 auto.commit.offset=false,手动 commit offset。
需要开发人员手动调用 commitSync(),将把 poll() 返回的最新的 offset,建议:
- 在 client 处理完 poll 回的所有数据后,再执行该方法,否则会冒着丢失消息的风险。
- 面对 rebalance 时,仍然存在重复消费消息的情况
Asynchronous Commit
commitSync() 会阻塞应用,直到收到 broker 的明确响应。这将很大的影响系统吞吐。可以考虑使用异步 consumer.commitAsync()
commitSync() 内部有 retry,如果遇到 retriable failure,会持续重试,影响性能,如果遇到 nonretriable failure,则会直接 commit fail。// todo retry count commitAsync() 没有 retry,之所以不支持 retry,是因为它本身是 async 的、非阻塞的。如果失败了又重试,可能会把这段时间发生的更新的 commit 的数据修改回去。当然了,如果真想重试,是可以找到解决方案的,如记录一个全局单调递增的 sequence number,重试前检查如果 offset 小于该 number,则取消 retry。
Combining Synchronous and Asynchronous Commits
对于手动控制 offset 的情况,commitAsync() & commitSync() 可以结合使用。正常情况下使用 async,提高性能,并且偶尔由于网络原因发生的失败也不需要 retry,一般都会在接下来的 commit 中成功,等待服务停止消费时,调用 sync,确保最终正确提交 offset。
Commit Specified Offset
commitSync() & commitAsync() 存在一个问题,只能在对 batch messages 全部处理完后,将最大的 offset 提交,无法做到更细粒度的控制。当处理 batch messages 的耗时很长,或者 batch 的消息个数很多时,如果在消费过程中发生了 rebalance,这次 poll 获取的所有 messages 都需要重新处理一次。
commitSync() & commitAsync() 都提供了带参数的方法,允许我们根据业务在消费 batch messages 的过程中按需要提交 offset。
Rebalance Listeners
在发生 partition rebalance 时(可能处在 processing batch messages 间隙),consumer 需要做一些 cleanup work,包括对正在处理的消息的收尾工作,对文件、数据库连接等的管理。我们可以通过在调用 consumer.subscribe() 方法中传入自定义的 ConsumerRebalanceListener 来实现。
ConsumerRebalanceListener 有两个方法需要实现:
- onPartitionsRevoked: 执行 rebalance 前的收尾工作,consumer 停止处理旧 messages 后 & rebalance 发生前系统调用该方法。可以通过该方法来 commit client 已处理的 offsets,这样能 commit 准确的 offsets
- onPartitionsAssigned: 执行 rebalance 后的初始化工作,partitions reassigned 后 & consumer 开始处理新 messages 前调用该方法
Consuming Records with Specific Offsets
seek(TopicPartition partition, long offset) seekToBeginning(TopicPartition tp) seekToEnd(TopicPartition tp)
Standalone Consumer: Use a Consumer Without a Group
有些情况下,consumer 会需要指定消费某些具体的 partitions, 而不是 join consumer group,由 consumer group 分配 partition & rebalance。可以调用 consumer.assign() 来实现该需求。
Kafka internal
Request processing
Kafka 的 request 分为:
- produce request
- fetch request
- metadata request
- and so on
Metadata request
kafka client 会定期向任意一个 broker(所有的 brokers 都拥有 partition metadata)发起 metadata request 来获取到每个 topic partition leader 的位置,并缓存在本地(有定期的缓存更新机制),从而在需要发送 produce or fetch requests 时正确的定位 broker 的位置。
如果缓存更新延迟,导致错误的 produce request 发到非 leader partition 的 broker 上,该 broker 会直接返回 error,而不是像 ElasticSearch 那样内部转发。
client 收到 produce/fetch response 的 “not a leader” error 后会 refresh metadata。
Produce request
produce request 的过程之前也聊过了,一个重要配置是 acks。
Fetch request
fetch request 由 consumer 或者 follower replicas 发起。
client 发起人request:
- 通知 broker 自己要 poll 的 messages 的 topics, partitions & offsets
- 可以设置 messages 数量的上限 & 下限,上限是为了防止 OOM,下限是为了减少网络次数。
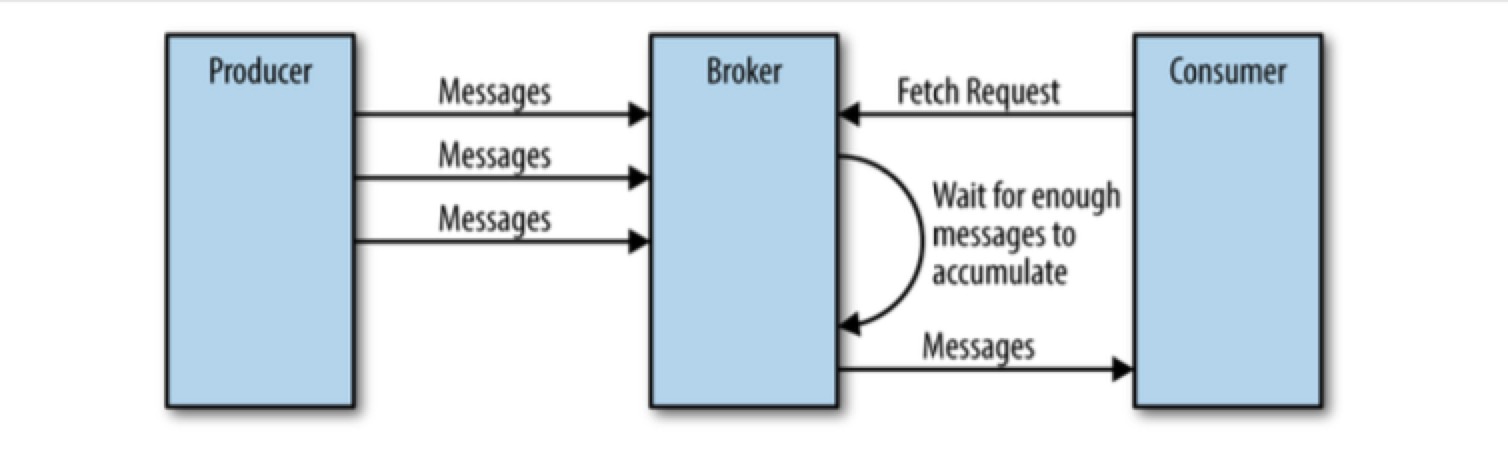
- 可以设置 timeout,如果 timeout 时间内,messages 量不够,也直接返回目前可以返回的 messages
consumers 只能 poll 到写入所有 replicas 的 messages,这是为了保证 strong consistency。 replication 是纯 async,有 lag 的,会导致消息无法第一时间到达 consumers。
broker 会校验 request 的正确性,包括 leader partition, offset。 broker 使用 zero-copy method 将 messages 发送给 client,大大增加了性能。 broker 处理 fetch request 的方式和处理 produce request 非常相似。
OffsetCommitRequest
过去,kafka 使用 zk 维护 consumers 的 offsets。当 consumer 启动时,向 zk 发请求获取要读的 partition 以及 offset。 但是因为频繁的读写 offsets 对 zk 的压力较大,所以推荐通过 Kafka broker 直接管理,现在 kafka 通过创建一个单独的特殊的 __consumer_offsets topic 来维护 offsets。
Physical Storage
我们会将 partition 在物理层面拆分成 segments。默认情况下,每个 segment 包含 1GB 的数据/一周的数据。当 broker 往 partition 中写数据时,如果当前 segment 的限制到了,会关闭该文件 & 创建一个新的。当前正在使用的 segment 叫做 active segment。每个 segment 会单独存储在 *.log 的物理文件中。
Indexes
由于 Kafka 支持 consumers 从任意可用的 offset 处读取 message,所以需要能快速的定位 message 所在的 segment 位置,Kafka 为每个 partition 创建有 index,index 维护从 offset 到 segment file 及 file 中的位置的映射。
index 也按照 segment 来拆分。
Compact
有一种场景,只保存相同 key 的最新的 message,就用到了 compact,将老旧的 message delete 掉。本质上也是一种 retention policy,技术细节这里不做介绍了。
这部分内容主要整理总结自 《Kafka The Definitive Guide》 Chapter 6: Reliable Data Delivery
Reliable
Kafka 的 components 有 producer, broker, consumer,整体服务的 reliable(可靠性) 依赖每一个环节的 reliable,需要 Linux administrators, network and storage administrators, and the application developers 共同努力。
最常为人知的 Reliability Guarantees 是 ACID,它只要用在关系型数据库中。
Reliability Guarantees
Kafka 提供的基本的 guarantee 包括:
- 单个 partition 中 messages 的 order
- produce 只有 messages 被写到所有的 replicas 时,该 messages 才被认为 “committed”
- acks: 0, producer 通过网络成功发出去就不管了
- acks: 1, producer 等到 leader 收到消息
- acks: all, producer 等到 message committed
- messages 只要 committed,就不会丢失,因为已经同步到所有 replicas
- consumers 只能读到 committed 的 messages
但是这种 guarantee 只能保证基本的 reliable,并不能保证 fully reliable。 系统中存在着 trade-offs,需要在 reliable 和 availability, high throughput, low latency, hardware costs 间做 trade-offs。
Using Brokers in a Reliable System
对于 reliable 的配置,可以配置在 broker level,也可以配置在 topic level。
Replication Factor
replication.factor 即副本总个数(包括 leader),这个参数在 topic 创建后,也可以手动修改的。 replication.factor 越大,会有越高的 reliability,但是会带来更大的备份延迟时间。
不同的 replicas 建议在不同的 brokers 上,而存有 partition replicas 的 broker 尽量在不同的 rack 上。
topic level 的配置是 replication.factor broker level 的配置是 default.replication.factor(针对自动创建的 topic)
in-sync
replication 是 kafka reliability guarantee 的核心。通过做 replication 来对抗 broker 的 crash。
in-sync replicas (ISR)
如何判断某个 replica 是处于 in-sync 状态呢:
- 不言而喻 leader 是 in-sync 的
- 与 zk 有活跃的 session,定期(默认 6s)给 zk 发送 heartbeat
- 在过去10秒(可配置)内从 leader 那里 fetch messages
- 在过去 10 秒内获取 leader 的最新消息。 也就是说,追随者仍然从领导者那里得到消息是不够的; 它必须几乎没有滞后。
可以看出:
- in-sync 是指 replica 处在活跃的持续同步数据的状态,但不代表 leader 的数据已经全部同步到 replica 中。即使 replica 处在 in-sync 状态,消息数据本身的同步也是有延迟的。
- 只要在一个时间周期内有同步操作,replica 就被认为是 in-sync 的,这会导致误判。如 replica 向 zk, leader 活跃过状态后,立马 crash(out of sync),但由于还没到下次同步状态的时间,此时 leader 会误以为此 replica 还是 in-sync 的。
什么情况下可能导致 replicas out-of-sync 呢:
- broker 在某些时间做 garbage collection,导致进程 pause 一段时间,此时会丢掉和 zk, leader 的链接,被认为 out-of-sync,在 gc 完后,重新链接 leader & zk,恢复回 in-sync 状态
- replica 处在的 broker crash/ network partition
Unclean Leader Election
clean leader election 是指当 leader unavailable(因为 broker unavailable) 时,kafka 会自动从 in-sync 的 replicas 中选举一个作为新 leader。所有 committed data(committed 是指 message 已经备份到所有 in-sync 的 replicas 中) 都不会丢失。
但是,当 leader unavailable 时,完全没有 in-sync replicas 存在时,该怎么办?参数 unclean.leader.election.enable 决定了这种情况发生时的处理办法,默认配置为 true。
假设存在 3 个 replicas,如果 2 个 followers 全变为 unavailable,leader 会继续接受 write request, followers 变为 out-of-sync。现在 leader unavailable,之前 unavailable 的 out-of-sync 的 followers 恢复后,系统如何抉择:
- 如果不允许 out-of-sync 的 replica 参与 election 变成新 leader,那么 partition 只能处于 unavailable 状态,直到之前的 leader 恢复。这种配置适合金融等强数据一致性问题的场景。
- 如果允许 out-of-sync 的 replica 变成新 leader,可能会丢失一部分写在老 leader 中的数据,可能引起不同 consumer group 读到的数据不一致。这种配置适合对数据一致性不那么敏感的场景。
可以看出,这也是在 consistency 和 availability之间做选择,符合 CAP 理论。默认为 true,说明 Kafka 倾向于选择 AP & weak consistency。 但是对于 consumer,由于只能读到写入所有 replicas 的 msg,所以可以理解为 strong consistency。
Kafka 的数据同步模式很像 Master / Slave Async。
Minimum In-Sync Replicas
min.insync.replicas 这个参数的意思有些晦涩,我读了两三遍才算理解。它是指 replicas 中,至少有几个 replicas 处于 in-sync 状态,leader 才会执行写请求,否则拒绝写。而不是 message 至少写入了几个 replicas。
假设有 3 个 replicas(leader 包含在内),如果 min.insync.replicas = 2,则当 producer 写 messages 时,至少要有两个 replicas 处于 in-sync 状态,leader 才会执行写入操作,否则返回 producer NotEnoughReplicasException。
所以该参数配置的越高,则 messages 越可能成功写入到更多的副本。如果该参数设置为 1,则 leader 不会关心其他 replicas 是否处于及时更新数据的状态,只要 leader 自身写没问题,就写入了,而其他 replicas 可能过很长时间才能同步到数据,这就增加了 leader unavailable 时,数据丢失的风险。
Using Producers in a Reliable System
上面说完了如何配置 broker 来尽量保证 reliable,但是如果 producer 配置不当,也会导致丢数据的情况发生。
ACK
考虑如下场景,partition 有 3 个 replicas:
- acks=0。producer 向 leader 发送请求时,如果 serialized error 或者 network fail 时,会返回 error,能成功发出去就认为写成功,但是 leader & replicas 在过程中出任何问题导致数据没写成功,都会造成数据丢失。
- acks=1。当 producer 向 leader 写消息,leader 写成功,返回 producer success,之后在数据还没同步到 replicas 时 crash,replicas 中的一个晋升为 leader。此时,producer 认为数据写成功了,但是 leader 却把这条数据丢失了。
- acks=all。可以规避第一种情况,但是,当 producer 向 leader 写消息时,leader 宕机了 & 新的 leader 还没选出来,producer 会收到 “Leader not Available” 。如果 producer 没有处理好异常,没有重试直到写成功,这条消息也会丢失。但是如果做好 error handle,是可以保证数据不丢失的。
单独 acks 的配置不能完全保证数据的成功存储。对于 producer 来说,为了保证 reliable,需要:
- Use the correct acks configuration to match reliability requirements
- Handle errors correctly both in configuration and in code
Retries
当有 error 发生时,需要进行 handle。error 分为两种:
- Retriable errors: KafkaProducer 针对这种异常,可以自动发起重试。全部逻辑隐藏在 send 方法中,开发人员不需要人工干预
- a connection error can be resolved because the connection may get reestablished.
- A “no leader” error can be resolved when a new leader is elected for the partition.
- Nonretriable errors: 这种错误没法通过重试修复,会直接抛异常,需要开发人员在代码层面处理
- message size too large error
- serialization errors
retry 也有风险:
- 可能造成消息被重复写入多次。考虑以下场景:broker 成功写消息,但是由于网络原因,没及时返回 ack,producer 认为消息创建失败,发起 retry,会导致消息写入两次。当然了,我们可以在 consumer 端解决这个问题,将 consumer 做成 idempotent 幂等的接口。
- producer 耗尽了 retry 次数
这些处理方式都需要根据业务需求,做出恰当的选择。
Using Consumers in a Reliable System
由于 Kafka broker 内部已经保证了返回给 consumer 的都是 committed data(保存到全部 in-sync replicas 中),所以 consumer 需要处理的事情就简单多了。但是 consumer 还需要能够正确的处理跟踪消息 offset & 处理消息,保证每次获取到的 message 的正确性,既不重复,也不缺失。
consumer 中有 4 个参数可以影响 reliable:
- group.id: 之前已经有过详细介绍
- auto.offset.reset: 控制当 consumer 提交的 offset 不存在,或者 consumer 刚启动 & offset topic 中没有记录过 offset 时的处理方法
- earliest: 可以导致重复处理消息
- latest: 可能导致遗漏处理消息
- enable.auto.commit: 这个配置很关键,是否让 consumer 自动提交 offset,或者开发人员在自己的代码中提交
- true: 好处,不需要开发人员写代码干预。坏处:可控性差,由于是周期性提交 offset,可能会重复处理消息。
- false: 好处,灵活控制提交频率
- auto.com mit.interval.ms: 如果 enable.auto.commit=true,这个配置自动提交的间隔周期,默认是 5s,周期越短,越能减少意外发生时,重复处理的消息数
Consumer retry
有时,当 consumer poll 到 messages 后,处理 messages 时会发生错误,如短暂的写入 db 失败,但是又不想丢失消息,这时可以:
- 存储消息到某个 buffer(本地 queue, redis, db…) 中,consumer 继续提交最新的 offset
- 存储消息到 kafka 中单独为这种情况创建的 topic 中,有专门的 consumer 来从该 topic 中消费
Stream processing
a stream is considered to be a single topic of data operate on the messages in real time
push 可以是实时的,poll 会有小小的延迟 push 无法根据 consumer 的消费能力动态调整发放速度,poll 可以动态调整
References
understanding-kafka-consumer-lag MQ 架构解耦 Kafka水位(high watermark)与leader epoch的讨论