在我们初步实现了机器学习算法后,可能会发现结果不尽如人意。训练集上运行很好的算法参数(cost function 很低),却在预测新数据(new examples)时误差很大(cost function 很高)。本篇博客主要关于评估学习算法的质量以及找出可能存在的原因。
为了评估学习算法的优劣,首先需要判断目前是处于 bias / variance。不同的处境需要不同的优化方法。
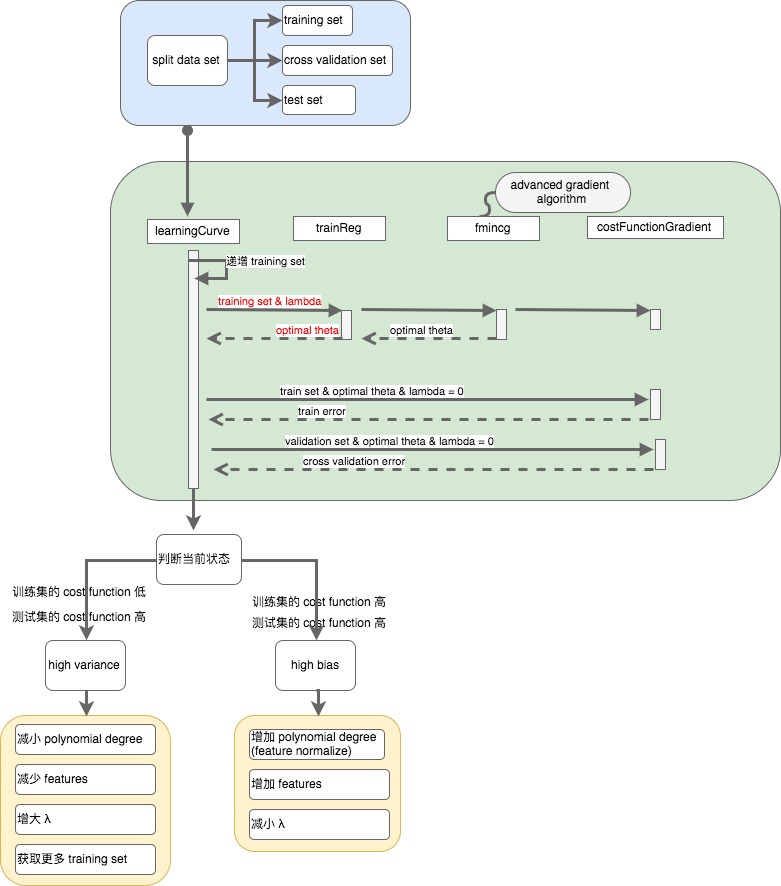
Split Dataset
首先将数据集分成三部分:training set \ cross validation set \ test set。三者的比例一般是 60% : 20% : 20%。
Bias vs Variance
在之前的帖子中我们谈到过 bias & variance。bias or variance 是算法质量较差的不同极端,其中:
- high bias(高偏差)是指 underfit,training set & test set 的 cost function 都很高。
- high variance(高方差)是指 overfit,training set 的 cost function 低,test set 的 cost function 很高。
Polynomial Degree and Bias / Variance
不同的算法可以拥有不同的多项式次数,而不同的多项式次数可能导向不同的 bias/variance。
随着多项式项数的增加,training set / cross validation 的cost function 呈不同的走势:
 可以看到,当 polynome degree 位于某个中间值时,cross validation 的 cost function 最小。
可以看到,当 polynome degree 位于某个中间值时,cross validation 的 cost function 最小。

具体次数多少最好,需要我们用 training set & cross validation set & test set 来评估。具体如下:

Regularization and Bias / Variance
当多项式的项数较高时,随之而来的是 overfit 现象,为了一定程度上消除 overfit,我们可以引入 regularization (正则化)。正则化中一个重要的参数是 lamda。该参数既不能过大(high bias/ underfit),也不能过小(high variance / overfit)。training set & cross validation set 随 lamda 变化的 cost function 的值的图如下:
 那么如何选择 model(polynomial degree) & lambda ?
那么如何选择 model(polynomial degree) & lambda ?

造成 high bias 的因素可能有 low polynomial degree /high lambda。 造成 high variance 的因素可能有 high polynomial degree / low lambda。
Learning Curves
Learning Curves 是一个很好的工具来检测当前算法是否处于高偏差、高方差或者两者皆有的情况。
除了 polynomial degree & lamda 影响算法预测的准确性外,数据集大小也是一个重要的因素。
当 training set 很小时,很容易做到 training set 的 cost function 零误差。随着 training set 数据量的增大,training set 的 cost function 值也在增大,而 test set 的 cost function 在逐步下降。但是对于不同的情况(bias / variance),cost function 的变化并不完全一样。
Experiencing high bias
training set & test set 的 cost function 都超过预期,且增加 training set 对算法的优化帮助不大。

Experiencing high variance
training set 的 cost function 在预期之内,但是 test set 的超过预期,增加 training set 对算法的优化有帮助。

可见,收集更多的数据并不一定会优化算法模型,只有当模型处于 high variance 时才有效。
Deciding What to Do Next Revisited
在了解了算法处于哪种问题后(bias / variance),我们可以选择不同的手段去优化:

Diagnosing Neural Networks
summary