今天计划将 Kafka, Elasticsearch, Redis, Zookeeper 放到一起来聊一聊。为什么要将这几个 Components 放一起比较呢,因为本质上来说,他们都是存储数据的:
- Kafka 存消息数据
- Redis 存缓存数据
- Elasticsearch 存搜索数据
- Zookeeper 通过 like-file-system 存配置信息
还有关键的一点,他们都是天然支持分布式存储的。而提到分布式存储,就不得不提:
- node role
- failure discovery
- leader election
- partition
- replication
- CAP
所以,这篇文章的初衷就是:比较不同分布式存储系统对不同问题的具体实现。接下来,我们梳理一下这篇繁杂文章应有的逻辑:
- 首先是 node role,它定义的不同节点的不同作用
- cluster 启动时进行 leader election
- cluster 正常启动后,进行数据的操作,需要处理 replication
- failure discovery:
- leader: leader election
- follower: drop or restart
- 最后是从整体上分析各个系统的 CAP 选择
- 部分系统涉及到 partition 的概念
我会尽我所能梳理清楚这些 key point 及其之间的关系。
CAP
关于 CAP,大神 Martin Kleppmann 提出了自己的见解,算是我读过的众多混乱的、语义不详甚至基本概念定义冲突的文章中的一股清流。他提出,CAP 定理本身太简单化而且被广泛的误解,以至于在描述系统上没有太多用处。文章地址推荐给大家: CAP written by Martin Kleppmann
Zookeeper
Node Role
zookeeper 中 roles 有:
- leader
- leader 处理所有的写请求(create, delete, setData)
- follower
- 只处理 client 发起的读请求(exists, getData, getChildren)
- 收到写请求后,forward 给 leader,然后从 leader 同步写操作
- 参与 leader election
- observer
- 只处理 client 发起的读请求(exists, getData, getChildren)
- 收到写请求后,forward 给 leader,然后从 leader 同步写操作
- 不参与 leader election
- 不参与强一致性同步(不参与 quorum)
- 单纯为了在不影响写性能的情况下,提高读性能
Quorum
Quorum 的作用:
- cluster state: zk cluster 正常运行所需的最少 server 数。在这里理解为参与投票的最少可用法定人数。
- leader election: 选举时最少需要 quorum 个节点认同,节点才能成为 leader。以避免 split brain,如果无法选出,则 cluster 将无法正常服务。
- consistency: replication 中,server 在返回 client success 前,最少写成功的 servers 数。这种意义上来说,和 kafka 中的 acks 是一个概念。
quorum 保证:只要当前集群整体正常(至少 quorum 个节点正常),写操作也得到 quorum 个节点 ack。当部分节点失效后,如果集群还整体正常,则一定有一个节点持有所有最新的数据。
ZAB (ZooKeeper Atomic Broadcast protocol)
Zab 是 Zookeeper 的 Consistency Algorithm,可以用它实现:
- leader election
- replication consistency
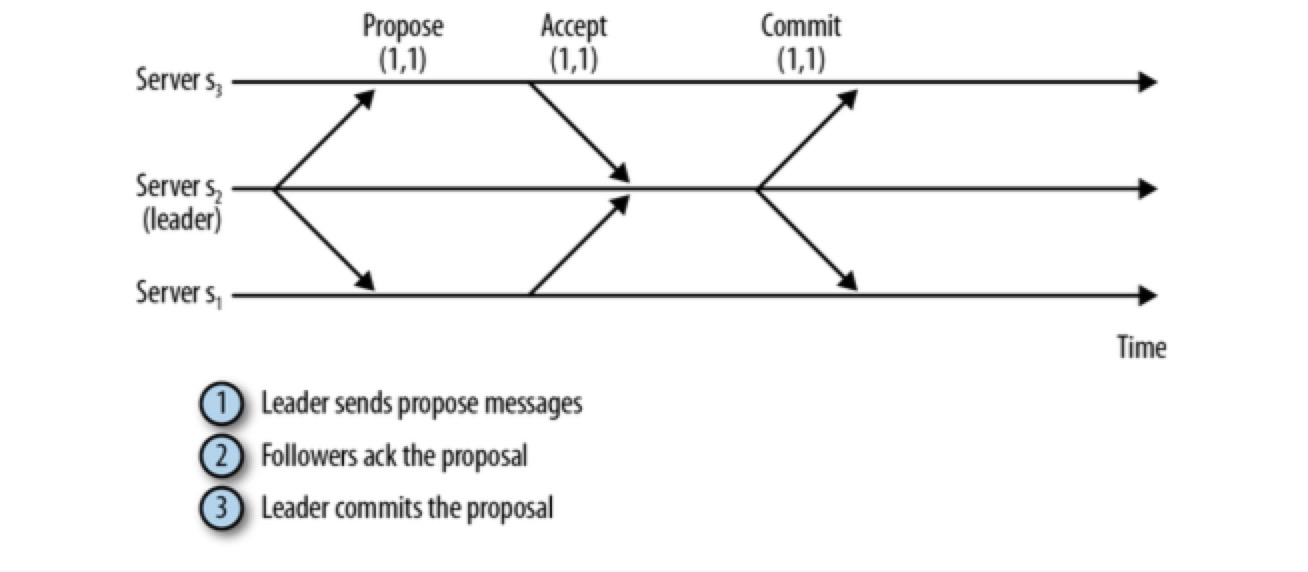
Zookeeper 通过 Zab 协议来进行 transaction commit 操作,ZAB 协议和 2PC 有相似之处:
- 接到 client 的写请求后,follower 将请求转发给 leader
- leader 向所有 followers 发送一个 proposal 消息,该消息中包含写事务
- 当 follower 接收到 PROPOSAL 后,会响应 leader 一个 ACK 消息,通知 leader 其已接受该提案(proposal)
- 当 quorum(包括 leader 自己) 个以上服务器回复 ack 后,leader 就会给整个集群发 commit 消息
- 之后 leader response client success
ZAB 保证:
- 事务在服务器之间的传送顺序的一致
- 服务器不会跳过任何事务
Replication
Zookeeper 可以理解成在至少 Quorum 个节点上同步复制
Zookeeper 是通过 ZAB 实现
- data replication
- leader election
Transaction
leader 将每一个写请求转换为一个 transaction,并分配 zxid。
ZXID
zxid 为一个64位 long 整数,分为两部分,每个部分32位:
- 时间戳(epoch)
- 计数器(counter)
zxid 主要有两个作用:
- 通过 zxid 对事务标识,就可以按照 leader 指定的顺序在各个服务器中顺序执行
- 服务器之间在进行新的 leader election 时交换 zxid 信息,哪个无故障服务器接收了更多的事务,就选举那个作为新的 leader
EPOCH
epoch 代表了管理权随时间的变化情况,epoch 的值在每次进行 leader election 时增加,一个 epoch 表示某个服务器行使管理权的这段时间。在一个 epoch 内,leader 根据 counter 定义每一个 transaction。zxid 可以很容易地与 transaction 被创建 epoch 相关联。
Failure Discovery
Zookeeper 可以通过临时节点来被第三方应用(如 Kafka)来实现故障检测,但是它自身的节点是如何通讯 & 实现故障检测的呢?
在每个 zk 的 zoo.cfg 中,配置了如下信息:
- tickTime=2000
- initLimit=5
- syncLimit=2
- server.1=192.168.20.105:2888:3888
- server.2=192.168.20.106:2888:3888
- server.3=192.168.20.107:2888:3888
tickTime
tickTime 是一个 tick 的时间,是后面配置的一个基准时间,以 ms 计量。
initLimit
initLimit:
- follower 初始连接到 leader 的最大 tick 次数。timeout = tickTime * initLimit
- follower 试图连接 leader 的最大时间,如果还连不上,就发起 leader election。
可以理解为 leader failure discovery 的配置。
syncLimit
syncLimit: leader 同步 follower (sending a request and getting an acknowledgement) 的最大 tick 次数。timeout = tickTime * syncLimit。
如果 leader 超过 syncLimit 个 ticks 还收不到 ack,就会在 cluster 中抛弃该 follower。
可以理解为 follower failure discovery 的配置。
Leader Election
- 每个服务器启动后进入 LOOKING 状态
- 如果 leader 已经存在,其他服务器会通知这个新启动的服务器,告知哪个服务器是 leader,与此同时,新的服务器会与 leader 建立连接,以确保自己的状态与 leader 一致
- 如果集群中所有的服务器均处于 LOOKING 状态,这些服务器之间广播发送 leader election notification 来选举一个 leader。
notification 包括该服务器的投票(vote)信息,投票包含
- 服务器标识符(sid)
- 最近执行的事务的 zxid 信息(epoch & counter)
Majority Vote
假设有 2f+1 个 Replica(包含 Leader & Follower),那在 commit 之前必须保证有 f+1 个 Replica 复制完消息。 为了保证正确选出新的 Leader,fail 的 Replica 不能超过 f 个。保证在剩下的任意 f+1 个 Replica 里,至少有一个 Replica 包含有最新的所有消息。
- 优点:系统的 latency 只取决于最快的几个 Broker,而非最慢那个。
- 缺点:为了保证 Leader Election 的正常进行,它所能容忍 fail 的 follower 个数比较少。也就是说,在生产环境下为了保证较高的容错程度,必须要有大量的 Replica,而大量的 Replica 又会在大数据量下导致性能的急剧下降。
这种算法更多用在 ZooKeeper(ZAB) 这种共享集群配置的系统中,但很少在需要存储大量数据的系统中使用
选举过程
- receiver 自己的 vote: myZxid & mySid
- receiver 收到的 vote: voteId & voteZxid
- If (voteZxid > myZxid) or (voteZxid = myZxid and voteId > mySid), vote = (voteId, voteZxid)
- else, vote = (mySid, myZxid)
经过多轮选举后,最终选出一个拥有最新 zxid & 被 quorum 的 nodes 同意的 leader。
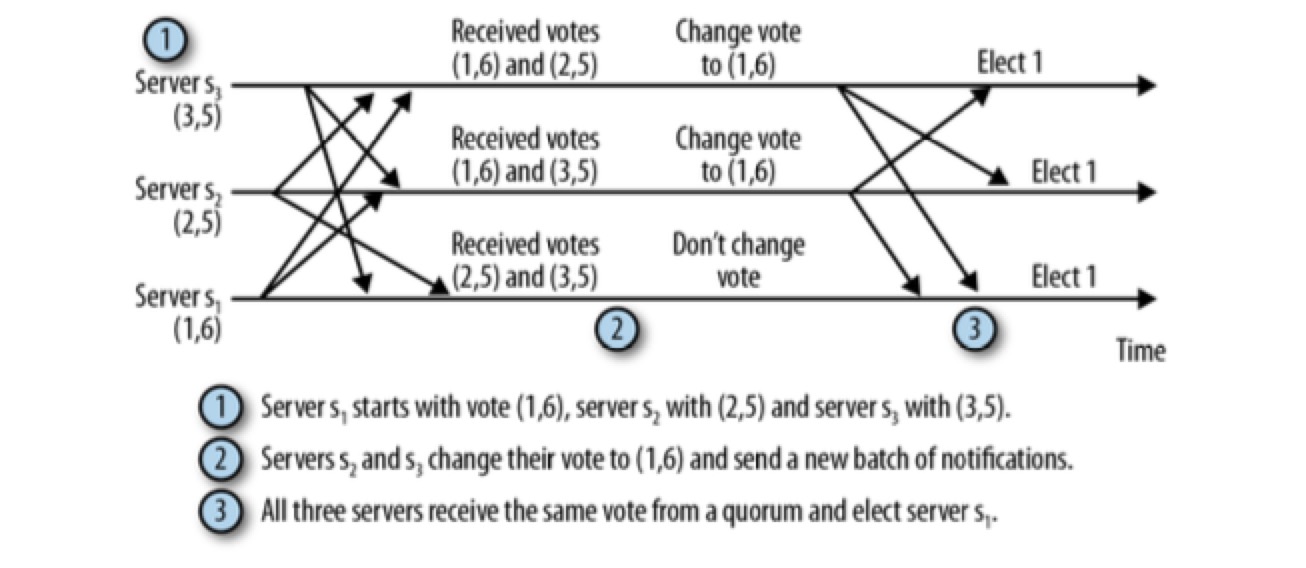 该图可以理解为 5 个节点的集群,其中 2 个故障后,剩下 3 个节点的 leader election 过程。
该图可以理解为 5 个节点的集群,其中 2 个故障后,剩下 3 个节点的 leader election 过程。
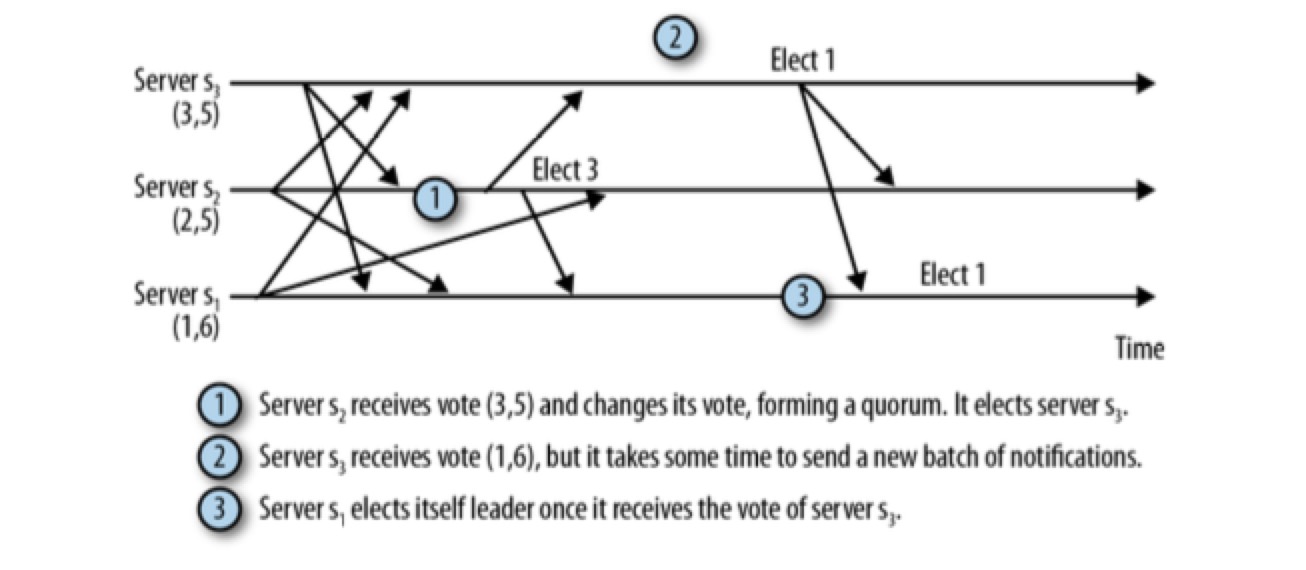
选举过程中的消息延迟
在从服务器 s1 向服务器 s2 传送消息时发生了网络故障导致长时间延迟,与此同时,服务器 s2 选择了服务器 s3 作为 leader 。但是服务器 s1 和服务器 s3 组成了仲裁数量(quorum)的 vote,将忽略服务器 s2。
FastLeaderElection
如果让 s2 在进行 leader 选举时多等待一会(无法确定需要等待多长时间),它就能做出正确的判断:
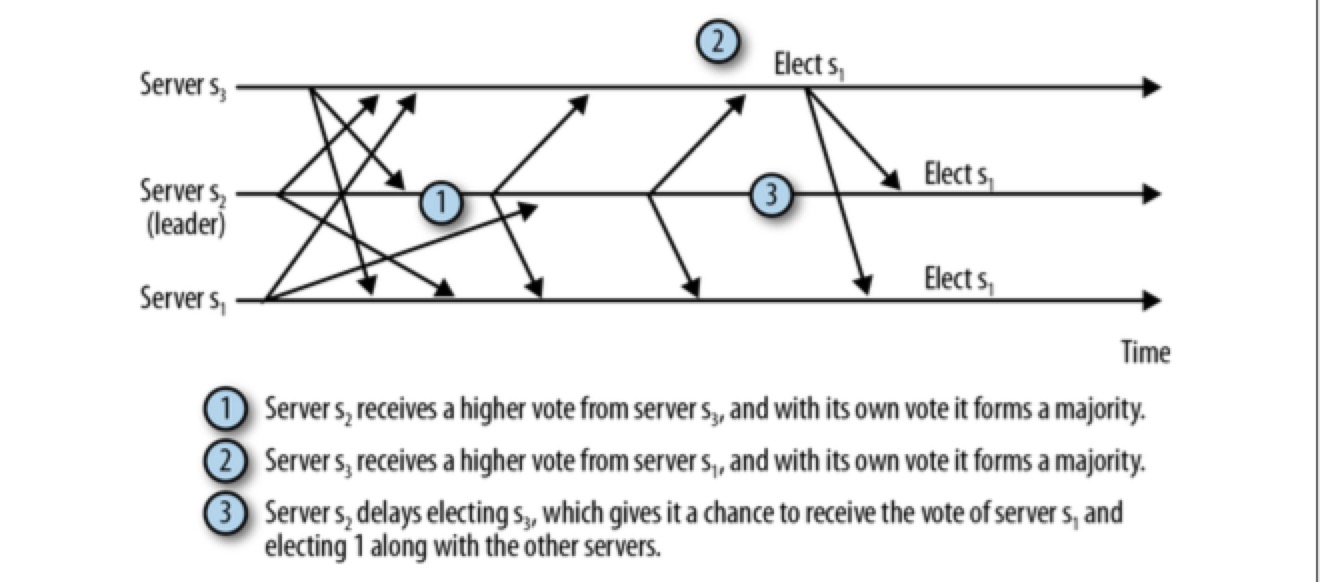
现实中,默认 leader election finalizeWait = 200ms
如果此延迟不够长,部分服务器可能错误地选择 leader,导致这轮 election 无法产生符合 quorum 的 leader,导致需要发送更多消息来继续执行 leader election,这会使整个恢复时间更长。
200ms 对于现代的数据中心消息延迟来说足够了。
选举成功后
- leader election 成功后,leader 节点告诉集群中的所有节点自己的 leader 身份
- 其他节点成为 leader 的 followers
- 新的 leader 同步自己持有的所有之前 epoch 的 transactions 给 followers
- DIFF(增量同步): minCommittedLog <= peerLastZxid <= maxCommittedLog,follower 和 leader 差距不大,leader 只发送最近的 transaction log
- SNAP(全量同步): peerLastZxid < minCommittedLog,follower 数据过于陈旧,ZooKeeper 会执行完整的 snapshot 传输(增加恢复时间)
- followers 更新完后,新 leader 才开始广播新的 transaction proposal
- 新的 transaction 的 zxid 都具有新的 epoch
可以看出,对于如 Zookeeper 一样持有状态(state/data) 的服务,leader election 和 replication 深深的结合在了一起。
CAP
ZooKeeper is a CP system with regard to the CAP theorem. This implies that it sacrifices availability in order to achieve consistency and partition tolerance. In other words, if it cannot guarantee correct behaviour it will not respond to queries.
关于 Zookeeper 的 CAP 讨论,请参考上面提到的马丁大叔的 post。
最终一致性
可以看到,ZAB 协议由于只要求 quorum 的 followers 发回 ack 消息,就会在集群间 commit。由于网络/服务器性能,提交并非在所有 servers 间实时完成,意味着可能有 client 连接的 server 读不到最新的数据,所以我理解,Zookeeper 默认是最终一致性系统。
强一致性
从 client 角度如果想保持强一致、读到的数据是最新的话,可以在读取前 sync 一下,这会使 client 连接的 server 从 master 同步最新的数据,那么之后读的就是最新的,可以实现 client 端的强一致性。
单调一致性
即使 client 不调用 sync,zk 也为 client 保证了单调性,即 client 不会读到比之前自己读到的数据还旧的数据,这主要是发生在 client 重连 server 时。zk 保证 client 不能连接到比自身已发现的 zxid 还旧的 server 上。因此,如果一个 client 在位置 i 观察到一个更新,它就不能连接到只观察到 i’<i 的 server 上。
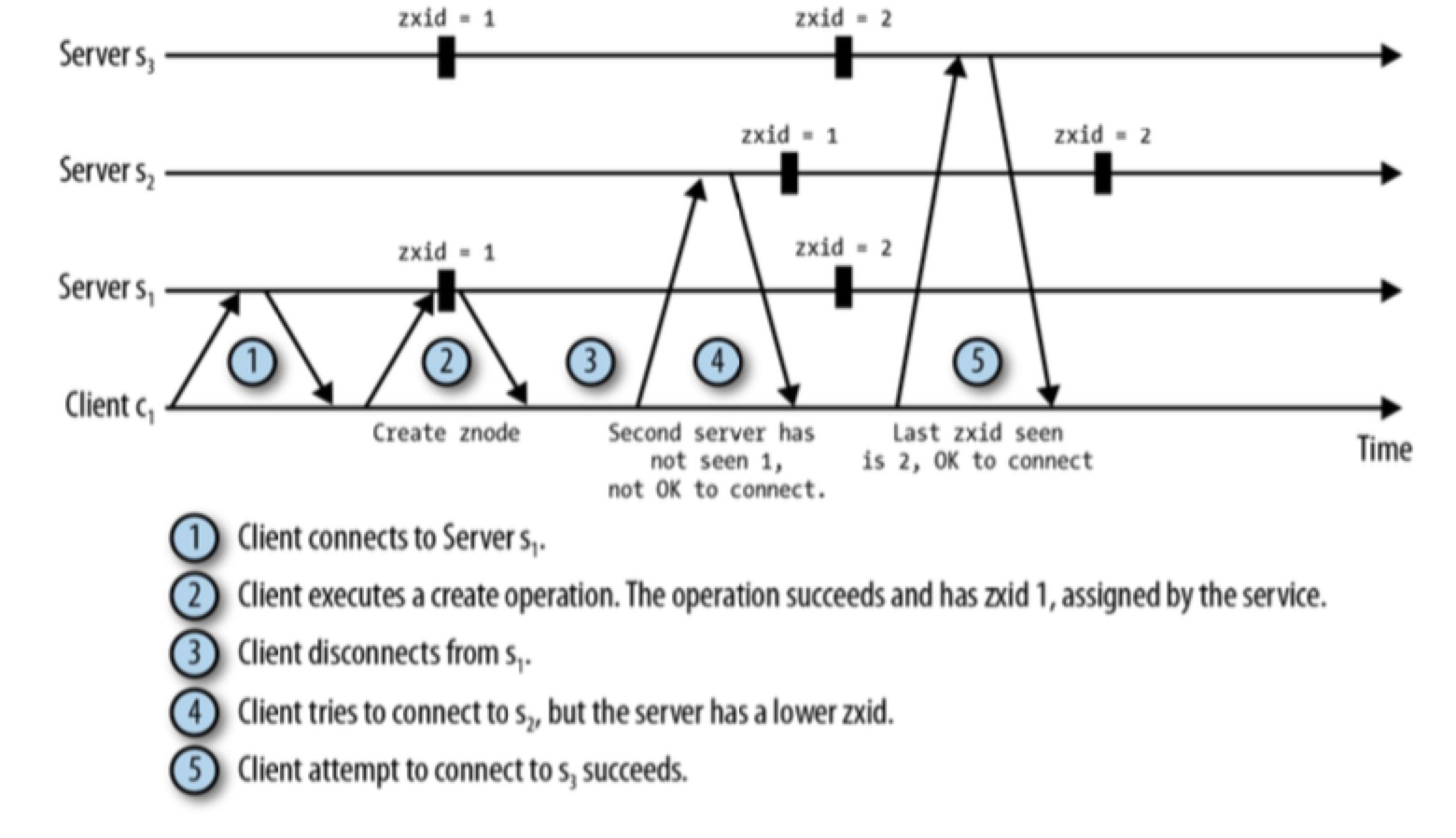
Partition
Zookeeper 不涉及到 Partition。
Application Leader Election by Zookeeper
除了 Zookeeper 本身的 leader election 后,由于 zk 作为分布式协调工具,很多分布式应用会使用 zk 来管理自己的 cluster 及 leader election,如 kafka。
- 初识时 app 通过抢占式的创建临时的 /master 节点来推选自己为主节点(我们称为“主节点竞选”)。如果 /master 已存在,app 在 /master 节点上设置一个监视点。
- app 创建一个有序的节点 /node/node-,ZooKeeper 在这个 znode 节点上自动添加一个序列号,成为 /node/node-xxx,其中 xxx 为序列号。当 master 宕机时,可以使用这个序列号来确定哪个 app 成为新的 master。
- 第 2 步也可以变成简单的所有 slaves 抢占 /master node。Kafka 就是这么做的。
Kafka
Node Role
Kafka 与 Zookeeper, Redis 的一个不同点在于,Kafka 需要对以下组件进行角色划分:
- broker cluster
- partition replicas
- consumer
Broker
- Broker
- 接受 producer 传递过来的 messages,store messages 到指定的 partition 中,并分配 offsets
- 接受 consumer 发过来的 poll messages request & heartbeats request
- Broker Controller
- 负责上面提到的普通 broker 的职责
- 通过 Zookeeper 监控 cluster 中别的 brokers 的健康状态
- 负责 partition leader 的选举
Partition
kafka 天然支持 partition,对于 partition 来说,也分两种角色:
- leader replica
- 负责该 partition 的所有读写操作(producer, follower replicas, consumer),通过这种方式来保证 strong consistency
- leader 还维护每个 followers 的同步进度
- follower replica
- followers 不直接承担 client 的读写任务。它们的唯一工作就是通过向 leader 发 fetch request 备份 messages。
Consumer
- consumer group common consumer
- 消费消息
- consumer group leader consumer
- 消费消息
- consumer group coordinator(broker) 发现某个 consumer 失联后,通知 leader 进行 rebalance partition
- 决定 consumer group 中哪个 consumer 消费哪些 partitions
Partition
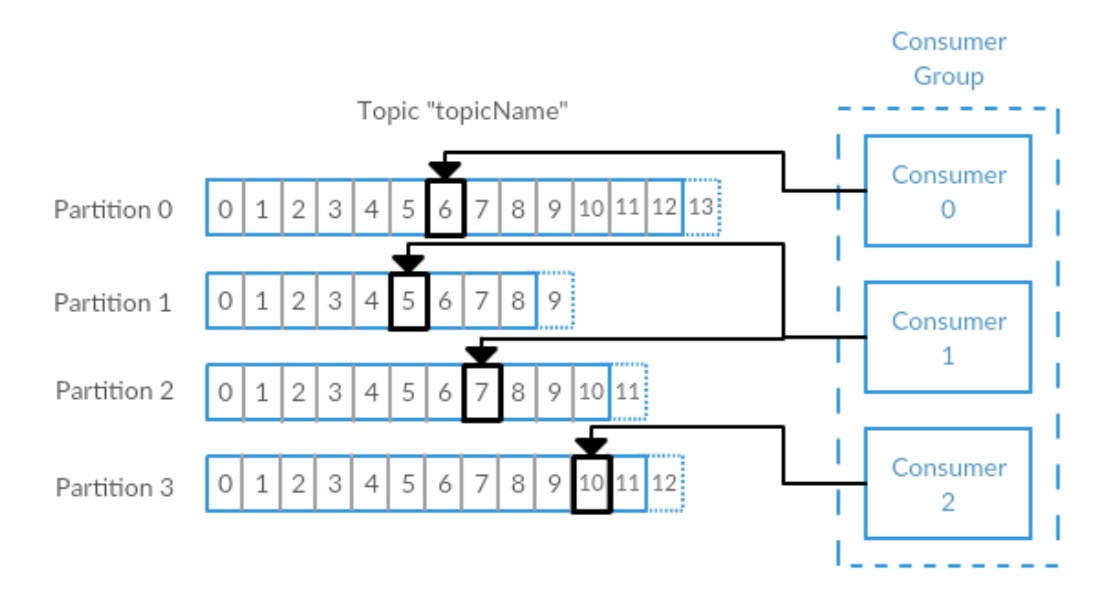 Kafka topic split 成多个 partitions,topic 中的 messages 分布到不同的 partitions 中,平衡负载,提高写性能,同时通过增加 consumer group 中 consumers 的个数,达到提高读性能的目的。
Kafka topic split 成多个 partitions,topic 中的 messages 分布到不同的 partitions 中,平衡负载,提高写性能,同时通过增加 consumer group 中 consumers 的个数,达到提高读性能的目的。
kafka 可以保证单个 partition 上的 msg 是有序的,但是在各个 partition 间,是无法维持一个全局有序的。
Broker Partition 策略
- 不指定 message 的 partition & key 参数,根据 round-robin algorithm ,随机落到某个 partition
- 指定 message 的 key 2.1 默认的 partitioner 对 key 应用一定的 hash 算法,来决定 partition 位置 2.2 默认的 key partition 算法在某些业务场景下,会导致各个 partition 的数据量严重不平衡。根据业务场景自定义 partitioner,对 key 应用自定义的算法来分配 partition 位置
- 指定 partition,则忽略 key,直接按照指定的 partition 去存储消息
Replication
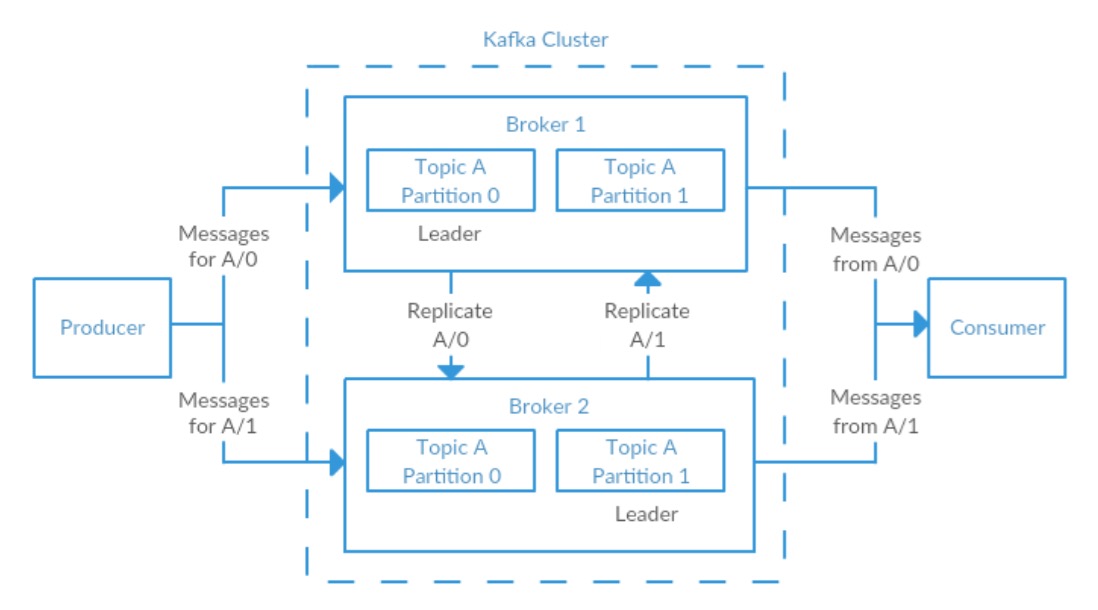
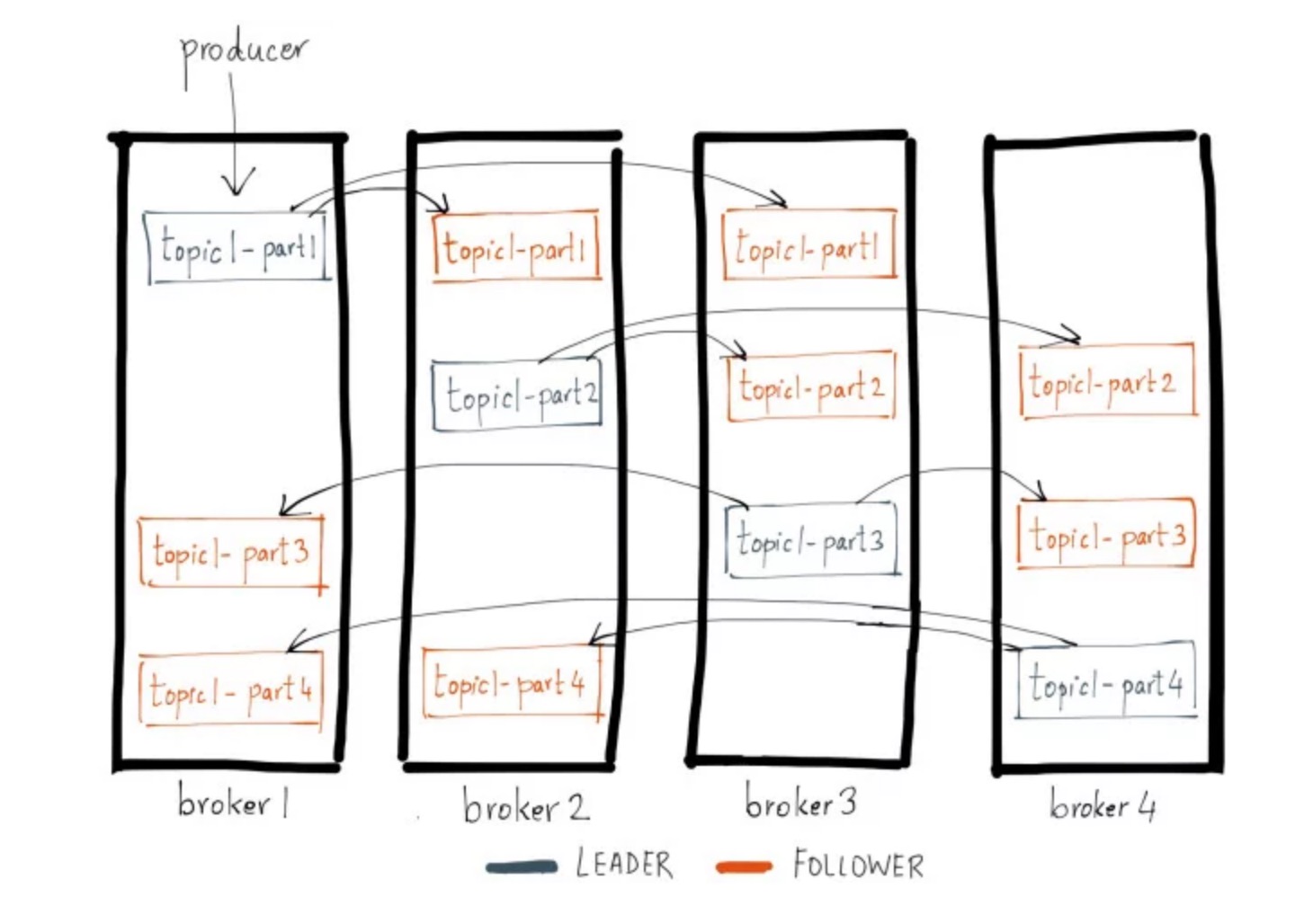
kafka official document Hands-free Kafka Replication: A lesson in operational simplicity
ISR
我们先来明确一个概念 in-sync replicas (ISR):
- 不言而喻 leader 是 in-sync 的
- 与 zk 有活跃的 session,定期(默认 6s)给 zk 发送 heartbeat
- replica.lag.max.messages: is set to 4 which means that as long as a follower is behind the leader by not more than 3 messages, it will not be removed from the ISR.
- replica.lag.time.max.ms: is set to 500 ms which means that as long as the followers send a fetch request to the leader every 500 ms or sooner, they will not be marked dead and will not be removed from the ISR.
需要注意:
- ISR 是指 replica 处在活跃的持续同步数据的状态,但不代表 leader 的数据已经全部同步到它中。即使 replica 处在 in-sync 状态,消息数据本身的同步也是有延迟的。
- replica 向 zk, leader 活跃过状态后,立马 crash(out of sync),但由于还没到下次同步状态的时间,此时 leader 会误以为此 replica 还是 in-sync 的。
Out-of-sync 的 replica 在条件允许下(网络正常)也会努力的去 catch up leader,直接 catch 住后,重新回到 ISR 中。
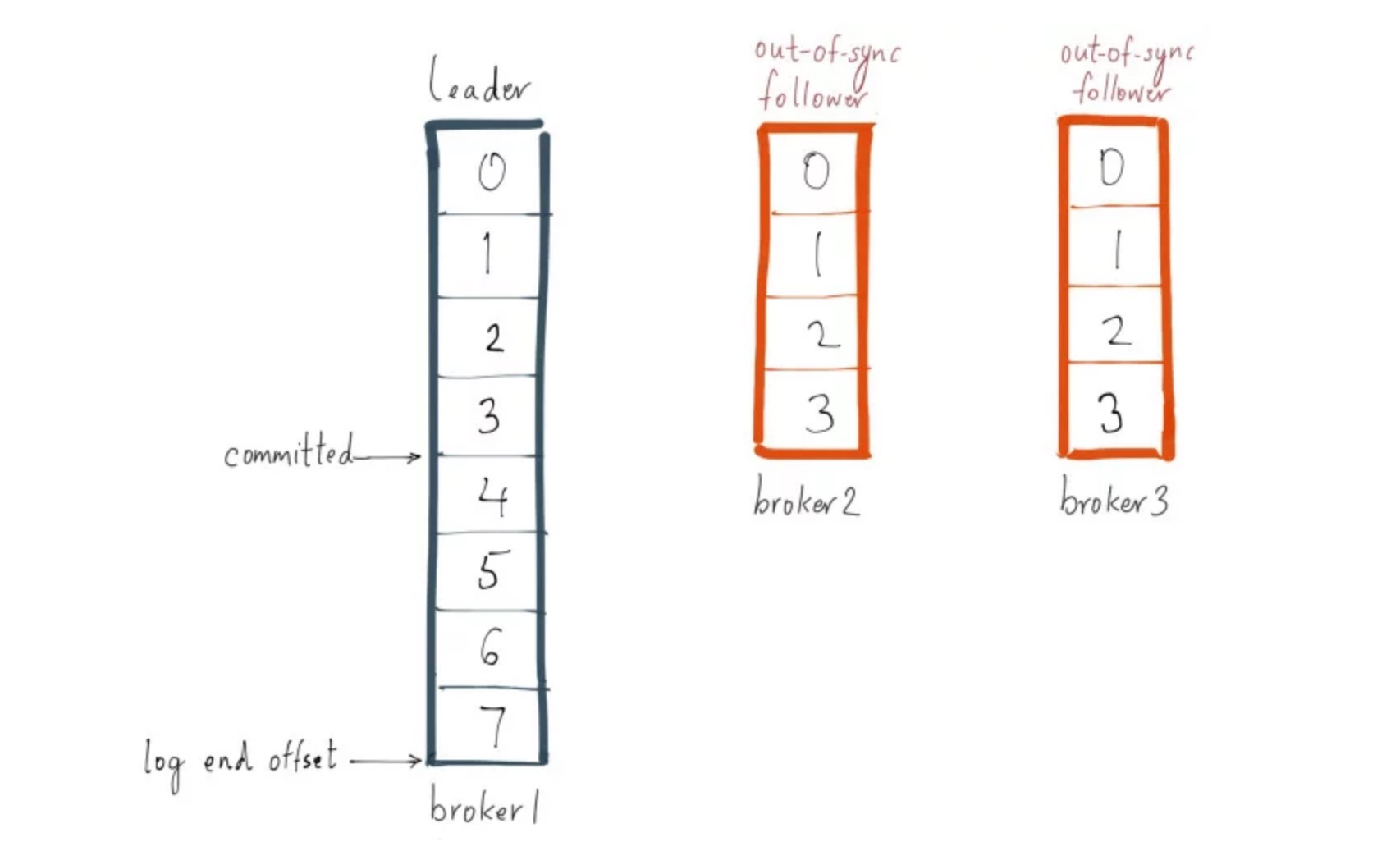
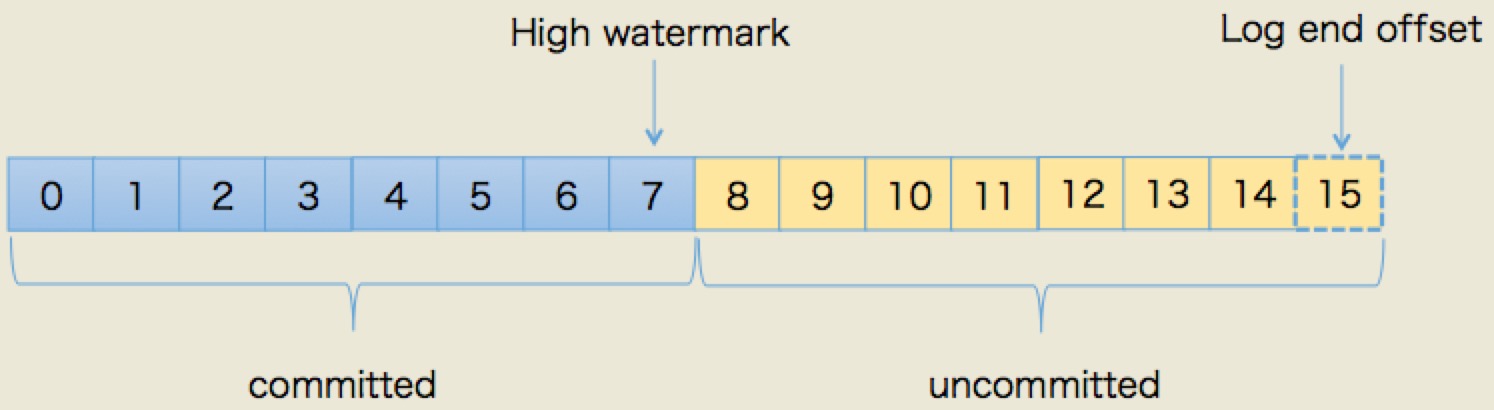
Offset & Log End Offset
- message:
- offset: 可以理解为 msg 在 partition 中的位置
- partition replica:
- log end offset:记录了所有数据最大的 offset。
- high watermark:replica 中 <= high watermark 的所有消息都被认为是在本 replica 已备份(replicated)到 log 中的。
ISR 收到消息 & 写入 log(replicated) 后回复 leader ack,如果某个消息被所有 ISR 都 ACK,就会被 leader 认为是 committed。consumer 无法获取到 uncommitted message。
Follower 是定期批量的从 leader fetch message,这样极大的提高复制性能(批量写磁盘)。 当 producer 设置 acks = 0, 1 时,producer 收到的 success response 不代表 message committed。
Failure Discovery
Broker Failure Discovery
broker 的 metadata 在 zookeeper 中维护。每一个 broker 都配置有自身唯一的 id,当 broker start 时,broker 将自身的 id 注册到 zk 中(通过写一个 ephemeral node)。
Follower Broker Failure Discovery
- Broker 启动时,会在 zk 上注册一个 ephemeral node
- Broker stop/ crash/ lose connectivity to zk/ long garbage-collection pause 时,它创建的 node 将被 zk 自动删除
- Controller broker 监听所有其他 brokers 的 ephemeral node 来识别 broker 的健康状况
Controller Broker Failure Discovery
- 第一个加入 cluster 的 broker 担任 controller,它会在 zk 中创建一个名叫 /controller 的 ephemeral node
- 当 controller broker stop/ crash/ lose connectivity to zk/ long garbage-collection pause 时,它创建的 /controller node 会被 zk 删除
- 其他 broker 监听该 /controller,如果被 zk 删除,其他 brokers 收到通知,开始选举
Consumer Failure Discovery
Consumer 都需要加入一个 Consumer group & 持有 n 个 partitions 的消费权。Consumer poll 消息 & commit 消费消息记录时,会发送 heartbeats 到 Kafka broker designated as the group coordinator 来同时告知自己的健康状况。
如果 consumer 由于 crashed or network failure 等原因长时间没有发送 heartbeats 到 group coordinator 时,group coordinator 会认为该 consumer 失联。
后续:group coordinator 通知 consumer group leader rebalance partition,group leader 将 rebalance 的结果通知 group coordinator,由 coordinator 来通知 consumers 新的 partitions 关系。
Leader Election
Broker Controller Election
触发场景:
- broker controller 失联时
Cluster 中别的 brokers 将被 zk 通知 controller 丢失,alive brokers 抢占 /controller node,第一个写成功的成为新的 broker controller。
Partition Leader Election
触发场景:
- broker controller 失联
- common broker 失联
Broker Controller 负责将之前在该 broker 上维护的 partition leader replica 从 in-sync 的 replicas 中选举一个作为新 leader。一个基本的原则就是,新的 Leader 必须拥有原来 committed data(committed 是指 message 已经备份到所有 ISR) 都不会丢失。
Kafka 动态维护 ISR(in-sync replicas,包含 Leader & follower)。当 partition leader crashes 时,拥有最多消息(最大 offsets)的 followers 将变成 leader。 新的 partition leaders 通知各个 brokers 中的 follower replica 需要 follow 的 new leader。
对于 2f+1 个 Replicas 的集群,消息被 commit 意味着:
- Zookeeper: 至少在 f+1 个 replicas 中 commit。最多容忍 f 个节点失败。
- Kafka: ISR 中都被 commit,但是 ISR 可能 = 0。最多容忍 2f 个节点失败。
正常情况下只有 ISR 里的成员才能被选为 Leader。 但不是绝对的从 ISR 中选择,通过配置 Unclean Leader Election 参数也可以在没有 ISR 存在时,从 out-sync replicas 中选 leader。
Consumer Group Leader Election
第一个加入 consumer group 的 consumer 就是该 group 的 group leader。
todo: 这块网上资料很少,需要后期看源码继续了解。