distributed application system & distributed storage system 为了解决相似的问题:
- Performance
- Availability (and fault tolerance) 提出相似的解决方案:
- 拆微服务 = 数据分片(partitioning)
- 服务冗余 = 数据备份(replication)
反过来,replication 会产生一致性问题,而一致性问题会影响性能 & 可用性:
strong consistency = great performance weak/eventual consistency = poor performance
根据 CAP Theorem:
strong consistency = weak availability weak/eventual consistency = high availability
Replication
Replication is making copies of the same data on multiple machines.
{kind=link}
好处:
- improves performance(read)
- by making additional computing power and bandwidth applicable to a new copy of the data, avoid a bottleneck
- reduce the distance between the client and the server(only in some specific replication strategy)
- improves availability: by creating additional copies of the data, increasing the number of nodes that need to fail before availability is sacrificed, avoid single point of failure
Replication 潜在的问题:
- node failure
- message latency / response latency
- network partition
- leader election …
Replication 中最重要的目标是保证各备份数据的 consistency ,使用某种 consistency model 来达到某种程度的 prevent divergence
- strong consistency model 对于 client 来说,操作这种类型的系统,就像操作 single system 一样简单。
- weaker consistency model 对于 client 来说,可能需要暴露一些技术细节。但能提供 lower latency & higher availability。
备份算法强调的是写算法,不同的写算法会影响读算法,最典型的如 NWR 算法。
备份算法可以从 同步备份/异步备份的维度来拆分,也可以按照一致性的强度来拆分。
Replication approaches
{kind=link}
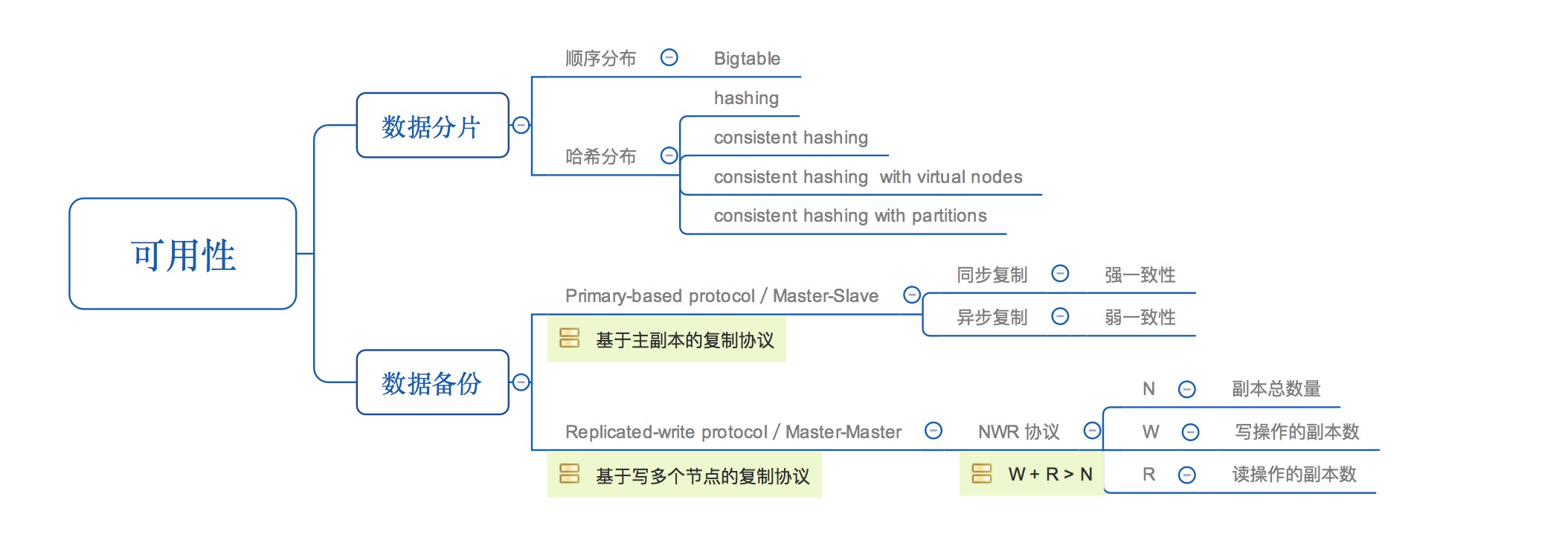
Synchronous replication
write N - of - N approach
master(leader / coordinator) 写成功后,会阻塞同步写 replies,等到全部 replies 响应(success or failure)后,才响应 client 执行结果(success or failure)。
- performance: 性能一般。需要 master slaves 的阻塞网络交互,整体响应时间取决于最慢的 server 执行的时间。
- strong durability guarantees: 只要 client 接到成功响应,就可以确定所有的 servers 都写成功了。
- strong consistency guarantees: 尽力提供强一致性保证吧
- tolerate: 系统不能容忍任何节点的 lost。slaves 没有回滚机制,只要有一个 server lost,整个 cluster 就不可写了,只提供只读功能。当然这其实是可以有一定妥协的。假如 Slave 宕机:
- 从数据角度: 整体执行失败,回滚 Master 并返回写失败 从服务角度: 只提供读能力,写请求全部拒绝
- 从数据角度: 在 Master & 正常的 Slaves 中写成功,fail 的节点写失败 从服务角度: 标记出错的 Slave 不可用,并继续提供读写服务,等出错 Slave recover 后同步 Master 的数据
如果 Master 宕机了,可以直接切换到 Slave。。。
Asynchronous replication
write 1 - of - N approach
master 处理完后立即发送 response 给 client。写操作日志会保存在 master 中,某段周期后,异步 Master push / Slave pull task 执行 replies ,当然,具体的细节要看不同的算法实现。Slave 可以有一个,也可以大于一个。大于一个时,同步写可以不要求全部副本都写完,只要有一个副本响应成功,主节点就可以回复客户端成功,但会降低一致性。
- performance: 比 synchronous 方式快,client 不需要等 cluster 内部所有节点操作成功,master 处理完后就可以直接响应 client.
- weak durability guarantees: 如果整个 cluster 正常运行,那么数据最终都会备份到所有机器。由于 replication lag 的存在,如果 master 在数据还没来得及备份到 slaves 时宕机,那么这段区间的数据都会永久性的丢失
- weak consistency guarantees: 最终一致性,不同节点读到的数据可能不一致 divergence * 当数据写入 master 后,备份到 slaves 需要周期,并且每个 slave 由于地理位置的区别,更新的时间也不一样 * 当某个节点 fail 后,新更新的数据没得到同步,recover 后,可能发生 data divergence
- available: 理论上只要有一个节点正常,服务就能运行
- tolerate: 对 network latency 的容错性较好
如果 Master 宕掉,会导致最后时间片内的写数据丢失:
- 如果不想让数据丢掉,Slave 只能成为 Read-Only 的方式等 Master 恢复(暂时牺牲服务的写功能)
- 如果可以容忍数据丢掉的话,马上从数据最全的 Slaves 中选举一个代替 Master 工作,经典的选举算法有 Paxos 协议。让 Slave
在实际使用时,正常情况下可以使用强一致模型,强同步复制,如果 Master Slave 之间出现网络故障,切换为最终一致性的弱同步复制模型,这样可以在一致性和可用性之间取得平衡。
Replication algorithms (consensus algorithm)
Single-copy(Strong) consistency algorithms
特点:
- 尽量保证 strong consistency guarantees,阻止 prevent divergence
- client 操作起来就像操作单机存储系统
1n messages (asynchronous master/slave) 2n messages (synchronous master/slave) 4n messages (2-phase commit, Multi-Paxos) 6n messages (3-phase commit, Paxos with repeated leader election)
Master-slave / Primary-Backup replication
- 写请求只由 Master 负责
- 读请求可以只由 Master 负责,也可以由 Master & Slaves 同时提供
- 写请求写到 Master 上后,由 Master 将 log 通过 network 同步到 Slave 上
Master-slave 的方式中,当 master 宕机后,需要人工手动的指定新的 master 节点。无法像 Paxos 一样,自动切换。 Master-slave replication 有很多的具体算法实现,他们基本遵循类似的消息传递模型,但是在处理 failover, replicas being offline 等问题上有各自不同的实现。
具体又分为:
- asynchronous master-slave replication
- synchronous master-slave replication
具体可参考上面 Replication approaches 提到的观点
asynchronous replication:
- 默认情况下 MySQL replication 使用 asynchronous 的变种
- 只能提供 weak durability guarantees
- master fail 后,还没同步到 slaves 的更新会丢失
synchronous replication:
- 只能提供相对较强的 durability guarantees
synchronous & asynchronous 可以理解成 1PC,没有回滚机制。当一部分 node success,而一部分 node failure or network partition 时,由于无法回滚,会导致 replicas diverge,无法保证 strong consistency guarantees。 为了保证 strong consistency guarantees,需要更多的消息交互,譬如 2PC。
我的理解,asynchronous replication 没发保持 single-copy consistency,需要再多阅读论文来深入学习这块。
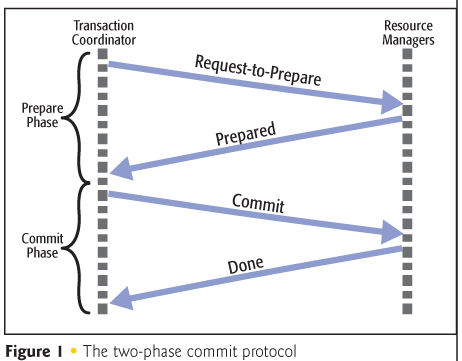
Two phase commit (2PC)
{kind=link}
在分布式系统中,每个节点虽然知晓自己的操作成功或者失败,却不知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持分布式事务的 ACID 特性,需要引入一个协调者来统一掌控所有参与者。。。。
2PC 把分布式事务分成两个过程,一个是准备阶段(Prepare Phase),一个是提交阶段(Commit Phase),实现分布式服务化的strong consistency。2PC 算法如下:
- first phase(voting):
- 协调者 coordinator 问所有的参与者 cohorts,是否可以执行提交操作
- cohorts 开始事务执行的准备工作:如:为资源上锁,预留资源,把 update 存储到 temporary area (the write-ahead log)
- 如果事务的准备工作成功, cohorts 回应 coordinator “可以提交”,否则回应“拒绝提交”
- second phase:
- 如果所有的 cohorts 都 vote “可以提交”,那么,coordinator 向所有的 cohorts 发送“正式提交”的命令。cohorts 完成正式提交,永久的保存数据,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个 Global Transaction。
- 如果任一 cohort 回应“拒绝提交”,那么,coordinator 向所有的 cohorts 发送 rollback,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个 Global Transaction。
2PC 有一些问题:
-
Node failure: 2PC 是同步阻塞的,任何指令必须收到明确响应,才会继续下一步。 First phase 某个 cohort 无响应时,系统处于 block 状态,占用的资源被一直锁定,直到 failure 的 node 恢复,所以 2PC 的性能较差 解决方案:可以设置 timeout,如果 coordinator timeout 后收不到 cohort 的响应,可以重试,也可以走 second phase 发起 failure rollback Second phase: 某个 cohort 没有收到消息/执行失败/节点失败时,会造成数据不一致性
-
Partition tolerant: 2PC 是 CA 系统,不支持 network partition tolerant,需要人工干预。
-
Coordinator single point failure:第一阶段完成后,如果参与者收不到协调者第二阶段的 commit/fallback 指令,那么结点会一直阻塞,block 住整个事务。解决方案: 3.1 人工介入 3.2 coordinator 构建 cluster, 失败发生时,选举新的 coordinator * 但是之前的那个操作仍然无法修复 * coordinators cluster 又会引入新的问题,如 cluster 健康检查,选举机制等
2PC 在传统的关系型数据库中比较流行,MySQL Cluster 提供的 synchronous replication 使用的是 2PC 算法。然而,现代分布式存储系统都需要满足 partition tolerant。当发生 network partitions 时,新的算法都需要提供自动恢复功能,以及更优雅的处理响应延迟。
2PC 的 coordinator 和 Master-Slave 中的 master 角色相似
2PC 比起 Master/Slave(1PC) 最大的优点在于有 rollback 机制
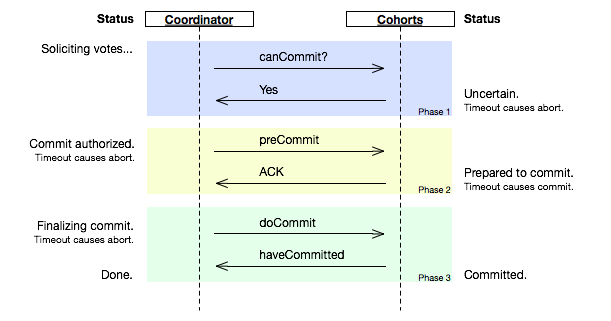
Three Phase Commit (3PC)
{kind=link}
3PC 是 2PC 的改进版本,他把 2PC 的第一个段 break 成了两段:在询问的时候并不锁定资源,除非所有人都同意了,才开始锁资源:
- 询问阶段:协调者询问参与者是否可以完成指令,协调者只需要回答是还是不是,而不需要做真正的操作,这个阶段超时导致中止。
- 准备阶段,这个阶段超时导致成功:
- 如果所有的参与者都返回可以执行操作,协调者向参与者发送预执行请求,然后参与者写 redo 和 undo 日志,执行操作,但是不提交操作;
- 如果任一参与者返回不能执行操作的结果,协调者向参与者发送中止请求。
- 提交阶段:
- 如果每个参与者在准备阶段返回准备成功,也就是预留资源和执行操作成功,协调者向参与者发起提交指令,参与者提交资源变更的事务,释放锁定的资源;
- 如果任何一个参与者返回准备失败,也就是预留资源或者执行操作失败,协调者向参与者发起中止指令,参与者取消已经变更的事务,执行undo日志,释放锁定的资源。
主要区别在于:
- 询问阶段可以确保尽可能早的发现无法执行操作而需要中止的行为,减少锁资源后又要 rollback 造成的资源浪费和阻塞
- 在准备阶段以后,协调者和参与者执行的任务中都增加了超时,一旦超时,协调者和参与者都继续提交事务,默认为成功,这也是根据概率统计上超时后默认成功的正确性最大。
最后,Timeout仍然可能会使系统发生不一致,你也不知道对方是做了还是没有做,这就需要运营或者技术人工解决。
2PC/3PC 是强一致性的方案,都包含多个参与者、一个事务包含多个阶段,实现复杂,性能并不好,因此,在互联网高并发系统中,倾向于使用改进后的 2PC,保证最终一致性。
Partition tolerant consensus algorithms 前面提到的 Master/slave replication(1PC), 2PC 都是不支持 partition tolerant 的,接下来我们谈谈兼容 partition tolerant 的 single copy algorithms。
比较著名的 partition tolerant consensus algorithms 有 Paxos & Raft & ZAB。
network partition 和 failed remote node 其实是比较难区分的。当 network partition 发生时,系统就 split 成两(多)个同时 active 的独立系统的了。但如果要在发生 network partition 时仍维持 single-copy consistency,就不能允许存在 symmetry 的多个系统,只能使一个 major partition 正常活跃,牺牲其他 partition 的 availability,这也满足 CAP 理论。 这也是为什么 partition tolerant consensus algorithms 依赖于 majority vote,选出 (N/2 + 1)-of-N 个 majority nodes 保持可用,其他不可达的节点停止服务以防 data divergence,系统能在确保 single-copy 的情况下正常运行,而不是像 2PC 要求所有的节点可用。 关于 majority vote 是另一个话题,我稍后再整理。
Paxos
Paxos is one of the most important algorithms when writing strongly consistent partition tolerant replicated systems. It is used in many of Google’s systems, including the Chubby lock manager used by BigTable/Megastore, the Google File System as well as Spanner.
2PC vs Paxos
- 2PC 协议用于保证属于多个数据分片上的操作的原子性,操作要么全部成功,要么全部失败。
- Paxos 协议
- 分布式系统中只要涉及到主节点的选举,都可以使用该算法
- 保证同一个数据分片的多副本之间的数据一致性
- 实现全局锁服务或命名和配置服务
常见的做法是将 2PC 和 Paxos 协议结合起来:
- 通过 2PC 保证多个数据分片上的操作的原子性
- 通过 Paxos 协议实现同一个数据分片的多个副本之间的一致性
- 通过 Paxos 协议解决 2PC 协议中协调者宕机问题。当 2PC 协议中的协调者出现故障时,通过 Paxos 协议选举出新的协调者继续提供服务
ZAB
ZAB - the Zookeeper Atomic Broadcast protocol is used in Apache Zookeeper. Zookeeper is a system which provides coordination primitives for distributed systems, and is used by many Hadoop-centric distributed systems for coordination (e.g. HBase, Storm, Kafka). Zookeeper is basically the open source community’s version of Chubby. Technically speaking atomic broadcast is a problem different from pure consensus, but it still falls under the category of partition tolerant algorithms that ensure strong consistency.
Raft
Raft is a recent (2013) addition to this family of algorithms. It is designed to be easier to teach than Paxos, while providing the same guarantees. In particular, the different parts of the algorithm are more clearly separated and the paper also describes a mechanism for cluster membership change. It has recently seen adoption in etcd inspired by ZooKeeper.
总结
Primary/Backup:
- Single, static master
- Replicated log, slaves are not involved in executing operations
- No bounds on replication delay
- Not partition tolerant
- Manual/ad-hoc failover, not fault tolerant, “hot backup”
2PC:
- Unanimous vote: commit or abort
- Static master
- 2PC cannot survive simultaneous failure of the coordinator and a node during a commit (block ?)
- Not partition tolerant, tail latency sensitive
Paxos:
- Majority vote
- Dynamic master
- Robust to n/2-1 simultaneous failures as part of protocol
- Less sensitive to tail latency
Weak consistency model
前面介绍了 strong consistency system,操作 strong consistency system 就像操作 single system 一样,相对简单。但是 strong consistency system 有自己的缺点:
- 维持一个全局正确的 order 是十分昂贵的
- 有些算法不支持 network partition(Master-slave, 2PC),有些算法为了支持 partition,部分程度上丧失了 availability(Paxos)
- 每一个写操作都需要大量的节点同步的消息传递(很多时候还不只传递一个消息),写性能差。虽然不同地理位置上的不同节点在可以满足不同地区的用户较高的读性能。
为了 single system 代价很大,但有些场合我们不需要 strong consistency,不需要一个绝对正确的值,返回一个基本正确的值就好。
eventual consistency system 的最大特点是:
- allow replicas to diverge from each other
- network partition 造成 diverge 时,每个 replica 仍然 available & accept writes and reads
- network partition heal 后,replicas 交换信息,但由于不同 replica 接受不同的 client 的写请求,已经 divergence,通过一些算法达成 consensus,保证 eventual consistency
由于 eventual consistency system 在 network partition 时,nodes 都可以 read-write,所有又可以理解为 Multi-master system / Master-master system / Replicated-write system。 git 源码冲突,对于同一行代码的冲突,记录版本号和修改者,需要交给开发者自己来处理。
eventual consistency 有两种分类:
- Eventual consistency with probabilistic guarantees This type of system can detect conflicting writes at some later point, but does not guarantee that the results are equivalent to some correct sequential execution. In other words, conflicting updates will sometimes result in overwriting a newer value with an older one and some anomalies can be expected to occur during normal operation (or during partitions). In recent years, the most influential system design offering single-copy consistency is Amazon’s Dynamo, which I will discuss as an example of a system that offers eventual consistency with probabilistic guarantees.
- Eventual consistency with strong guarantees This type of system guarantees that the results converge to a common value equivalent to some correct sequential execution. In other words, such systems do not produce any anomalous results; without any coordination you can build replicas of the same service, and those replicas can communicate in any pattern and receive the updates in any order, and they will eventually agree on the end result as long as they all see the same information.
CRDT’s (convergent replicated data types)
CRDT’s (convergent replicated data types) are data types that guarantee convergence to the same value in spite of network delays, partitions and message reordering. They are provably convergent, but the data types that can be implemented as CRDT’s are limited.
The CALM (consistency as logical monotonicity)
The CALM (consistency as logical monotonicity) conjecture is an alternative expression of the same principle: it equates logical monotonicity with convergence. If we can conclude that something is logically monotonic, then it is also safe to run without coordination. Confluence analysis - in particular, as applied for the Bloom programming language - can be used to guide programmer decisions about when and where to use the coordination techniques from strongly consistent systems and when it is safe to execute without coordination.
Amazon’s Dynamo
Amazon’s Dynamo system design (2007) is probably the best-known system that offers weak consistency guarantees but high availability. It is the basis for many other real world systems, including LinkedIn’s Voldemort, Facebook’s Cassandra and Basho’s Riak.
Dynamo is an eventually consistent, highly available key-value store. A key value store is like a large hash table: a client can set values via set(key, value) and retrieve them by key using get(key) . A Dynamo cluster consists of N peer nodes; each node has a set of keys which is it responsible for storing.
it does not guarantee single-copy consistency. Instead, replicas may diverge from each other when values are written; when a key is read, there is a read reconciliation phase that attempts to reconcile differences between replicas before returning the value back to the client.
if the data is not particularly important, then a weakly consistent system can provide better performance and higher availability at a lower cost than a traditional RDBMS.
Consistent hashing
In Dynamo, keys are mapped to nodes using a hashing technique known as consistent hashing, 参考。。。
Just like Paxos or Raft, Dynamo uses quorums for replication. However, Dynamo’s quorums are sloppy (partial) quorums rather than strict (majority) quorums.
Quorum protocols
full strict quorum
a strict quorum system is a quorum system with the property that any two quorums (sets) in the quorum system overlap. Requiring a majority to vote for an update before accepting it guarantees that only a single history is admitted since each majority quorum must overlap in at least one node. This was the property that Paxos, for example, relied on.
majority quorum
sloppy (partial) quorums
Partial quorums do not have that property; what this means is that a majority is not required and that different subsets of the quorum may contain different versions of the same data. The user can choose the number of nodes to write to and read from:
- the user can choose some number W-of-N nodes required for a write to succeed;
- the user can specify the number of nodes (R-of-N) to be contacted during a read.
W and R specify the number of nodes that need to be involved to a write or a read. Writing to more nodes makes writes slightly slower but increases the probability that the value is not lost; reading from more nodes increases the probability that the value read is up to date.
The usual recommendation is that R + W > N , because this means that the read and write quorums overlap in one node
assuming R + W > N : R = 1 , W = N :fast reads,slow writes R = N , W = 1 :fast writes,slow reads R = N/2 and W = N/2 + 1 :favorable to both
典型场景: Dynamo. Facebook’s Cassandra is a Dynamo variant that uses timestamps instead of vector clocks(Dynamo).
NWR
NWR 是 Replicated-write protocol 的一种实现协议
NWR 模型把 CAP 的选择权交给了用户,让用户自己的选择你的 CAP 中的哪两个。 N 代表 N 个总备份数(一般设置 3+),W 代表要写入至少 W 份才认为成功,R 表示至少读取 R 个备份。配置的时候要求 W + R > N,所以 R > N - W,也就是说,每次读取,都至少读取到一个最新的版本。
当需要高可写时,可以配置 W = 1 R = N。只要写任何节点成功就认为成功,但读的时候必须从所有的节点都读出数据 —> 弱一致性,高可用性。 当需要高可读时,可以配置 W = N R = 1。必须写所有节点成功才认为成功,这时读任何一个节点成功就认为成功 —> 强一致性,低可用性
Amazon Dynamo 用了数据版本的设计,就像“乐观锁”一样,但是会有版本冲突的问题:
- 一个写请求,第一次被节点 A 处理了。节点A会增加一个版本信息(A,1)。我们把这个时候的数据记做D1(A,1)。 然后另外一个对同样key的请求还是被A处理了于是有D2(A,2)。这个时候,D2是可以覆盖D1的,不会有冲突产生。
- 现在我们假设D2传播到了所有节点(B和C),B和C收到的数据不是从客户产生的,而是别人复制给他们的,所以他们不产生新的版本信息,所以现在B和C所持有的数据还是D2(A,2)。于是A,B,C上的数据及其版本号都是一样的。
- 如果我们有一个新的写请求到了B结点上,于是B结点生成数据D3(A,2; B,1),意思是:数据D全局版本号为3,A升了两新,B升了一次。这不就是所谓的代码版本的log么
- 如果D3没有传播到C的时候又一个请求被C处理了,于是,以C结点上的数据是D4(A,2; C,1)。
- 如果这个时候来了一个读请求,W = 1 那么 R = N = 3,所以 R 会从所有三个节点上读,此时,他会读到三个版本: A结点:D2(A,2) B结点:D3(A,2; B,1); C结点:D4(A,2; C,1)
- 这个时候可以判断出,D2已经是旧版本(已经包含在D3/D4中),可以舍弃。
- 但是D3和D4是明显的版本冲突。于是,只能交给调用方自己去做版本冲突处理。就像源代码版本管理一样。
上述的配置用的是 CAP 里的 A 和 P。
references
十分推荐: Distributed systems for fun and profit
An introduction to distributed systems A Note on Distributed Computing
Scalable Web Architecture and Distributed Systems Scalable Web Architecture and Distributed Systems 中文翻译
Distributed Systems: Principles and Paradigms Notes on distributed systems for young bloods
Fallacies of distributed computing
陈皓:分布式事务 Google I/O 2009 - Transactions Across Data centers Using sagas to maintain data consistency in a microservice architecture by Chris Richardson A Taxonomy of Distributed Storage Systems Distributed systems theory for the distributed systems engineer
Dynamo: Amazon’s Highly Available Key-value Store Bigtable: A Distributed Storage System for Structured Data Megastore: Providing Scalable, Highly Available Storage for Interactive Services
CAP Theorem: CAP Theorem by Wikipedia CAP Theorem: Revisited Distributed Computing in Microservices: CAP Theorem
clock: Lamport clocks Vector_clock
知识点
- FLP
- CAP
- Paxos
- Two Generals problems
- Byzantine Generals problems
- Gossip protocols
- Consensus protocols
- Back Pressure
- Bully algorithm(Leader election)
分布式系统实现
- Dynamo
- Cassandra
- GFS
- Spanner
- Chubby
- BigTable
- Zookeeper
- Redis
- RabbitMQ