前几天总结了 Redis 的基本功能及使用技巧,今天计划从缓存的全局角度总结下知识点。 缓存的使用场景:
- 开销大的,需要复杂计算的数据
- 请求量大的数据
缓存的作用:
- 提升系统整体性能,缩短访问时间
- 降低数据库压力
缓存带来的问题:
- 数据不一致
- 代码维护成本
- 缓存服务,如 redis 的运维成本
缓存的处理主要是指:
- 写
- 读 时,缓存的处理方式。
缓存分类
- 分布式缓存:如 redis, memcached 等
- 本地进程内缓存:将一些数据缓存在服务的进程内,可以通过带锁的 Map 来实现
| 策略 | 优点 | 缺点 |
|---|---|---|
| 分布式缓存 | 由专业的 redis 集群管理数据一致性问题 灵活伸缩容 |
延时稍高 |
| 本地进程内缓存 | 进程内缓存省去了网络开销,一来节省了内网带宽,二来响应时延会更低 | 多机部署时,服务和服务间缓存数据的一致性难保证 |
分层架构设计,有一条准则:服务层要做到无数据无状态,这样才能任意的加节点水平扩展,数据和状态尽量存储到数据库或缓存服务中。
缓存模式
- Cache Aside Pattern(旁路缓存)
- Read/Write Through Pattern(穿透模型)
- Write Behind Caching Pattern
Cache Aside Pattern
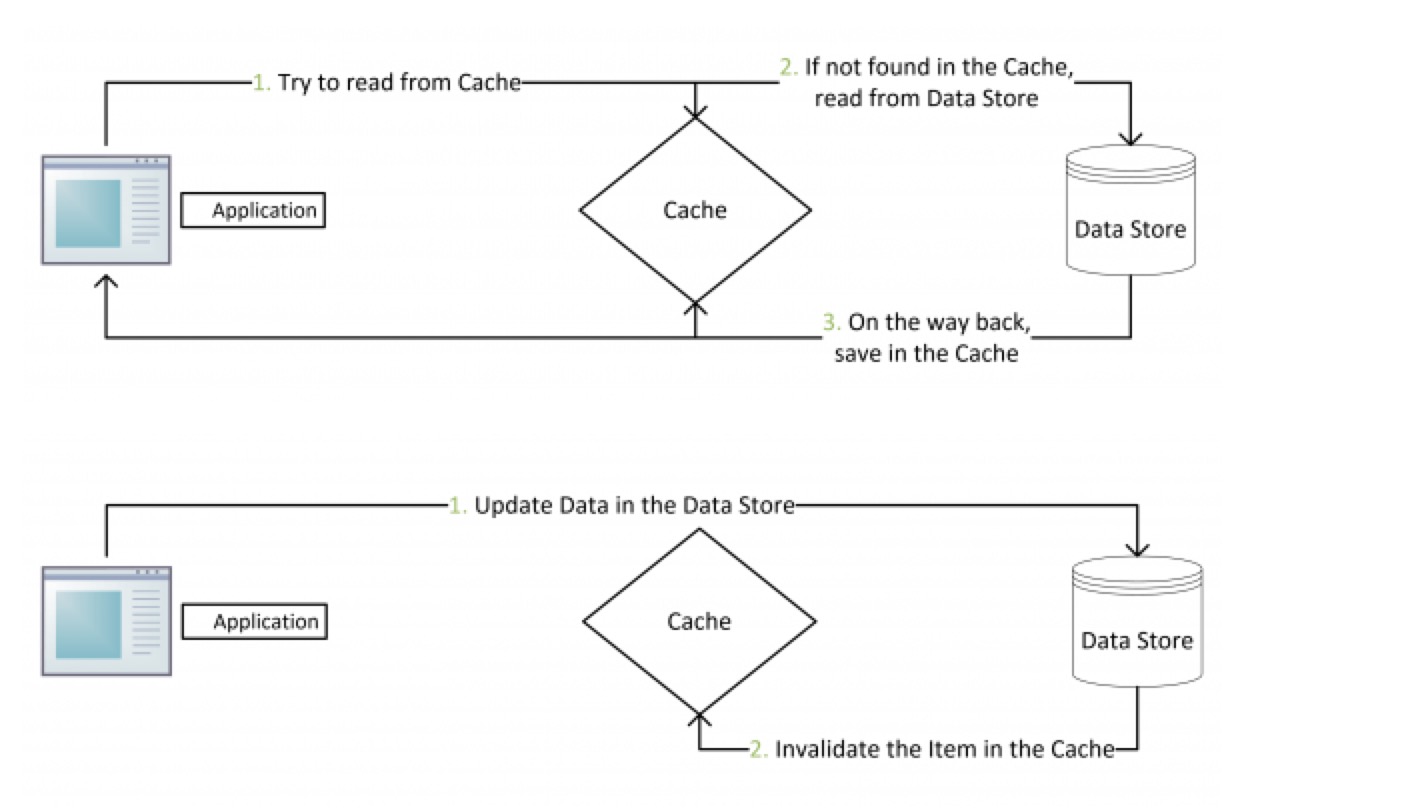
- 写:先更新数据库,成功后,让缓存失效
- 读:
- 命中:应用程序从 cache 中取数据,取到后返回
- 失效:应用程序从 cache 中取数据,没有得到,则从数据库中取数据,成功后,放到缓存中
cache aside pattern 是主流的缓存模式
Read/Write Through Pattern
Cache Aside 中,应用代码需要维护两个数据存储: 缓存(Cache)& 数据库(Repository)。所以,应用程序比较复杂。 Read/Write Through 是把更新数据库(Repository)的操作由 cache 代理了,这对于应用层就简单多了。可以理解为,应用认为后端就是一个单一的存储,而 cache 维护自己和 repository 的一致性。
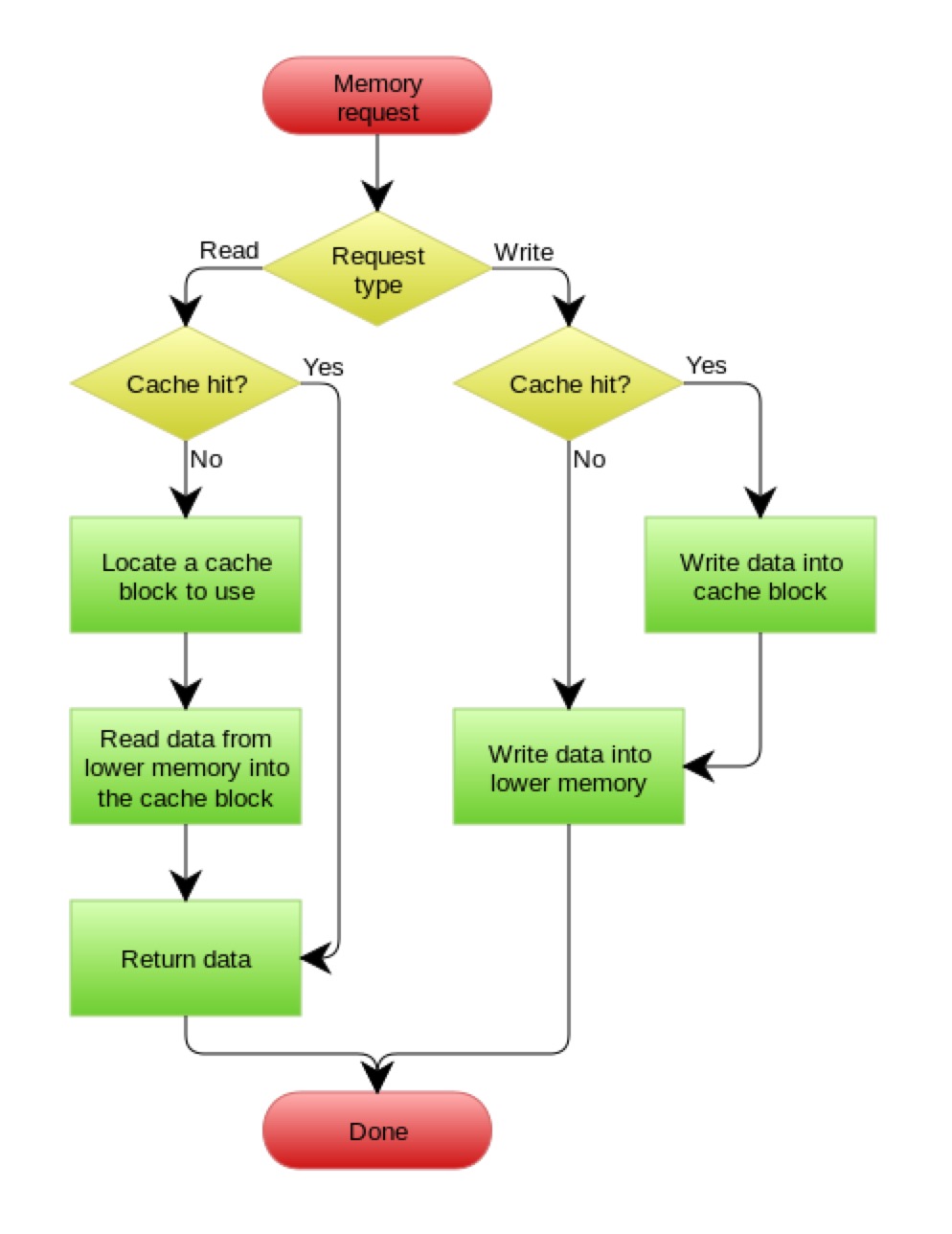
数据源数据更新后,淘汰缓存 or 更新缓存
- 淘汰 key 操作简单,直接将 key 置为无效,下一次访问该 key 会 cache miss & read from db
- 修改 key 的内容,逻辑相对复杂,但下一次访问该 key 会 cache hit
一般情况下,建议直接 del cache:
- 为了保证写的速度,就直接 del cache。特别是在 update cache 比较耗时时,如 object serialize
- 更新存在高并发下的存入脏数据的风险
更新缓存
如果需要在更新数据库的同时更新缓存,则需要通过 2PC 或是 Paxos 等协议保证一致性,但来的问题就是性能的大幅下降
一致性:缓存数据和真实数据的一致性
缓存粒度控制
| 数据粒度 | 占用空间,网络流量 | 维护成本 |
|---|---|---|
| 粗粒度 | 大 | 低 |
| 细粒度 | 小 | 高(增减时,需要修改代码) |
穿透
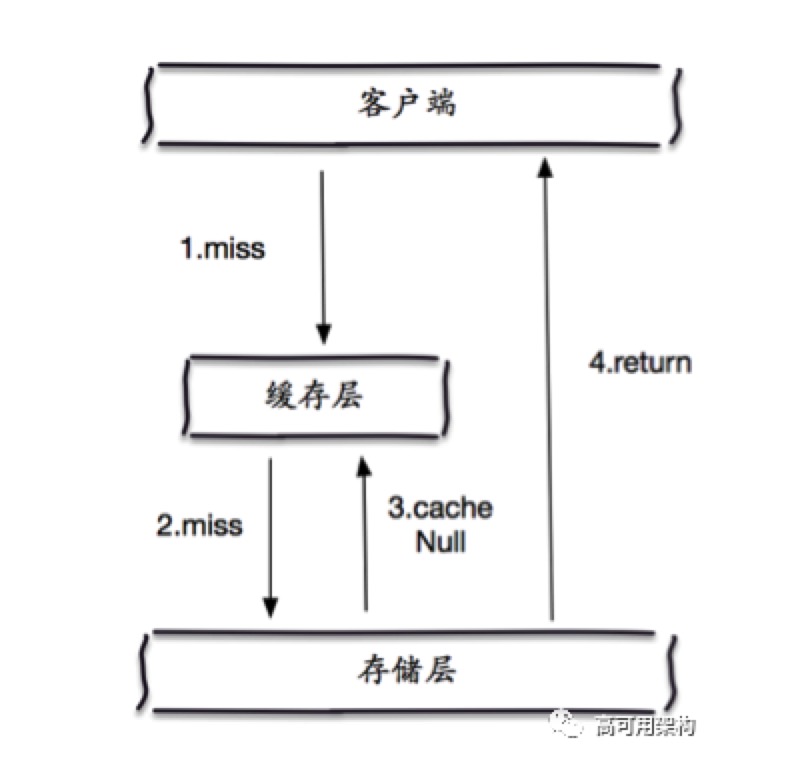
缓存穿透是指:查询一个不存在的值,缓存 & 数据库都不会命中(不会将 null 写入缓存)。这将导致每次查询不存在的值都去数据库查询,使得后端数据库压力过大。
如何识别缓存穿透:大量的数据库存储层未命中(返回 null)。
解决方案:
- 缓存空对象:如果数据库不命中,将空对象写入缓存,并设置一个较短的过期时间
- bloom filter:将存在的 key 用 bloom filter,如 redis 中的 bitmaps
| 策略 | 维护成本 |
|---|---|
| 缓存空对象 | 需要较多的缓存空间 |
| bloom filter | 需要较少的缓存空间 |
雪崩
如果缓存宕机,则所有请求都会打到数据库存储层,导致数据库压力过大,甚至宕机。
解决方案:
- 保证缓存层的 HA:replication & partition
- 提前做容量规划,判断 db 层的抗压力
- 业务层面,限流降级
无底洞
添加更多的缓存服务器后,性能不升反降。
原因:对数据做 partition 后,不同的 key 分布在不同的 servers 上,导致批量操作(mget, mset 等)从原先的操作一台机器,变成需要操作多台机器,多次网络耗时。
解决方案:
- 串行 IO:在 client 上将 key 归档,然后串行对每个归档后的 keys 执行 mget or pipeline 操作
- 并行 IO:在 client 上将 key 归档,然后并行对每个归档后的 keys 执行 mget or pipeline 操作
- hast_tag:redis cluster 通过 hash_tag 可以将多个不同 key 的数据强制分配到一个 node 上。
| 策略 | 优点 | 缺点 | 网络 IO |
|---|---|---|---|
| 串行 IO | 编程简单 性能一般还过得去 |
node 很多时,性能差 | O(nodes) |
| 并行 IO | 并行调用,延迟取决于最慢的节点 | 编程复杂 多线程带来的调试困难 |
O(max_slow(nodes)) |
| hast_tag | 性能最高 | 业务维护成本高 容易造成数据倾斜 |
O(1) |
热点 key 重建
对于热点 key,如果失效后,同时会有大量的 client 调用数据库 & 重建缓存,但其实这是非常浪费资源的。
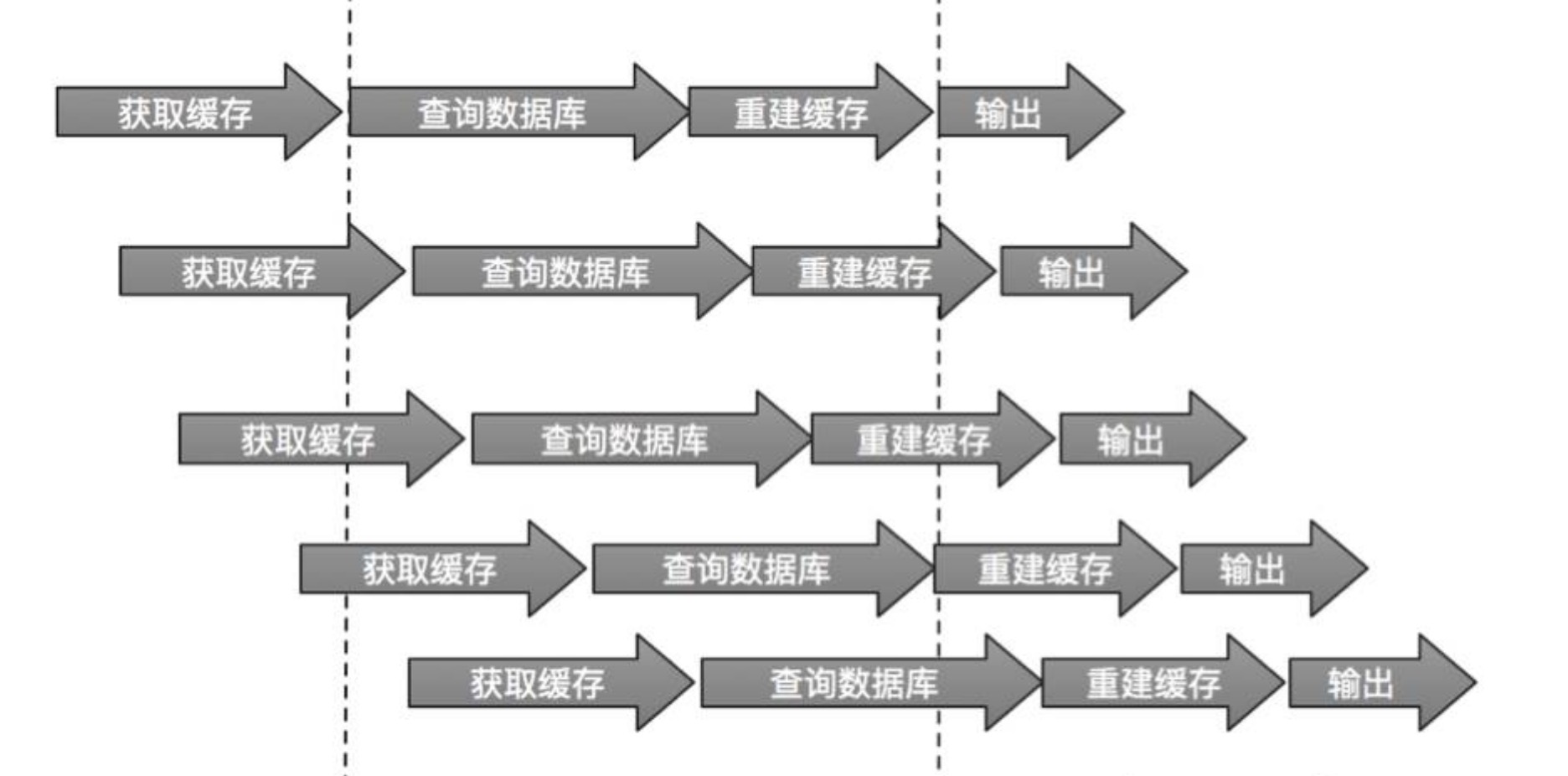
解决方案:
- 互斥锁,保证同一时刻,只有一个 client 发起读库 & 重建缓存
- 不设置过期时间:
- 缓存层不设置
- 功能层,定期由单独的线程更新
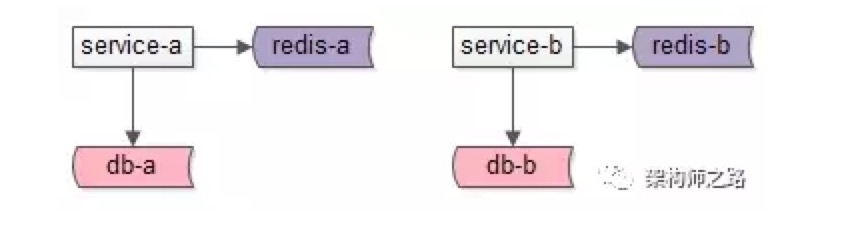
多服务使用缓存
- 每个服务有自己的 redis
- 所有服务访问同一个 redis
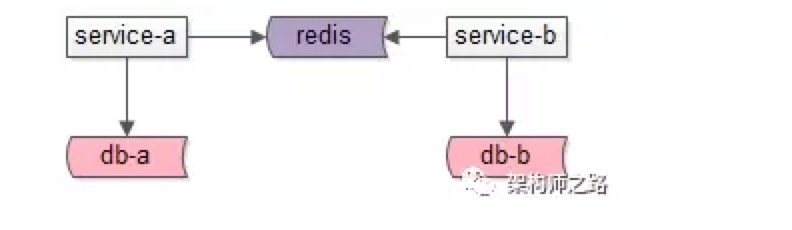
所有服务访问同一个 redis 存在的问题是:
- 可能导致 key 冲突,冲掉对方的数据。为了避免风险,可以使用 namespace:key 的方式来区分。
- 不同服务对应的数据量,吞吐量不一样,共用一个实例容易导致:
- 一个服务把另一个服务的热数据挤出去
- 一个服务操作不当,阻塞住单线程的 redis,导致别的服务也不可正常使用
- 与微服务架构的 “数据库,缓存私有” 的设计原则相悖