What is Redis?
Redis 特点:
- 内存型、非关系型数据库
- C 语言实现
- 单线程架构 & I/O 多路复用模型
- 丰富的数据结构
- 支持 persistence
- 支持 replication(master-slaves)
- 支持 partition(cluster)
- 支持 ha 高可用(sentinel)
丰富的数据结构:
- STRING
- LIST
- SET
- HASH
- ZSET
- Bitmaps
- HyperLogLog
- GEO
丰富的功能:
- 键过期
- pub/sub
- pipeline
- transaction
- lua
为什么单线程架构能这么快:
- 纯内存访问
- 非阻塞 I/O 多路复用
- 单线程避免了线程切换和竞态产生的消耗
由于上面提到的原因,所以 redis server 执行命令是非常快的,这时,真正影响 client 响应速度的更多时候是网络,由此有了如下解决方案:
- mset, mget, hmget 等原子性命令
- pipeline 非原子命令。一个网络,多个请求
- transaction
带来的问题:
- 如果某个操作很耗时,那么将级联阻塞别的线程的命令
Web requests in this type of situation are considered to be stateless in that the web servers themselves don’t hold information about past requests, in an attempt to allow for easy replacement of failed servers. by reducing traditional database load by offloading some processing and storage to Redis, web pages were loaded faster with fewer resources.
Why Redis?
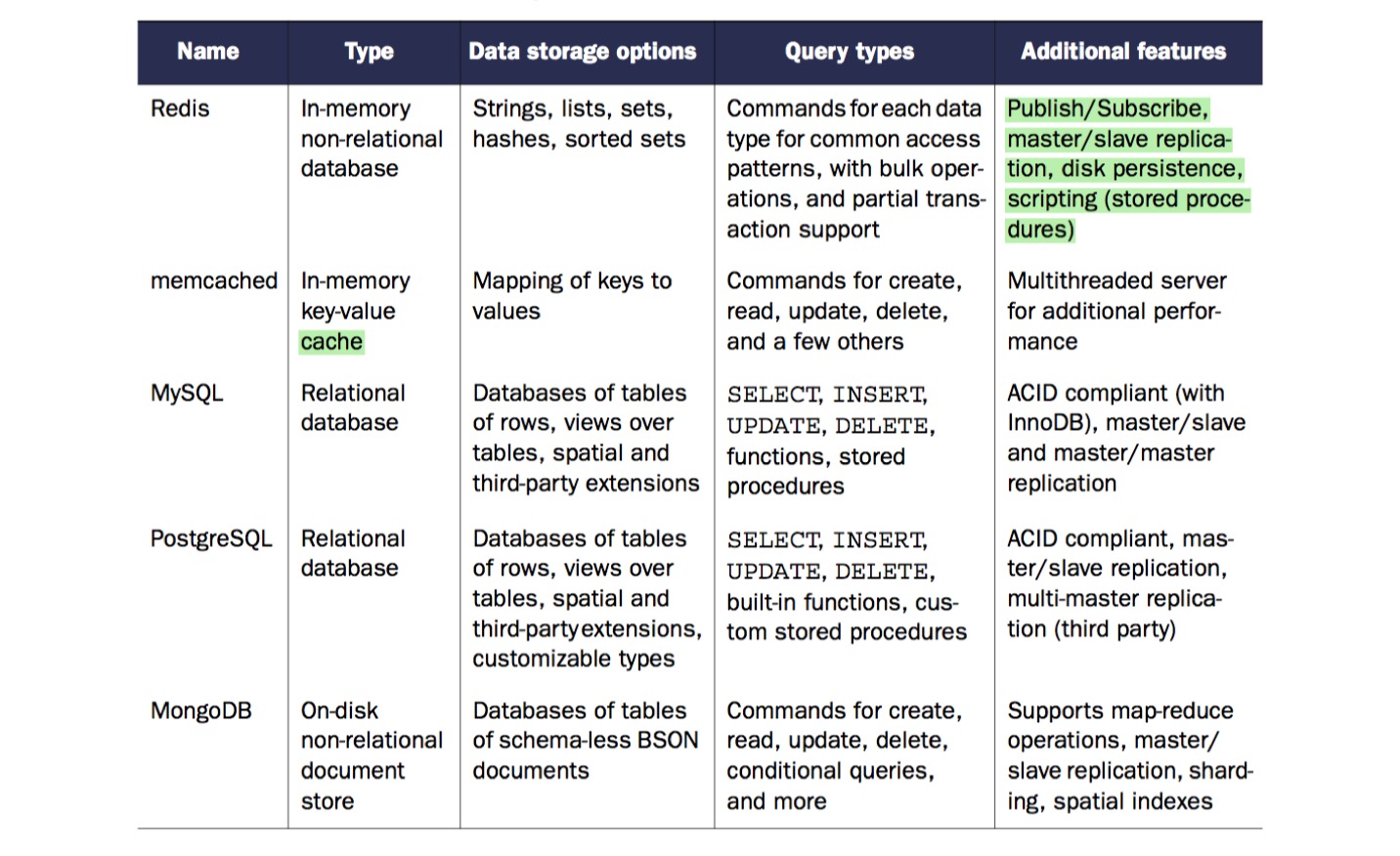
Redis vs memcached
redis 的优点:
- redis 有比 memcached 更完善的数据结构。list, set, hash, zset 在业务中可以发挥非常大的作用。
- redis 有持久化的保证,某种程度可以使用 redis 来部分替代 db。memcached 没有持久化功能
- redis 天然支持 sentinel & cluster,服务监控,故障自动转移,这些对于 client 都是透明的。memcached 需要二次开发
- redis 允许的 value size 较大
memcached 的优点:
- 内存分配:memcached 使用预分配内存池的方式管理内存,能够省去内存分配时间。redis则是临时申请空间,可能导致碎片
- 线程模型: memcached 使用多线程,主线程监听,worker子线程接受请求执行读写,这个过程中,可能存在锁冲突。redis 使用单线程,虽无锁冲突,但难以利用多核的特性提升整体吞吐量。
Redis vs relational databases
- 内存型数据存储,比传统关系型数据库读写都快
- 支持数据的 expired
Data Structures
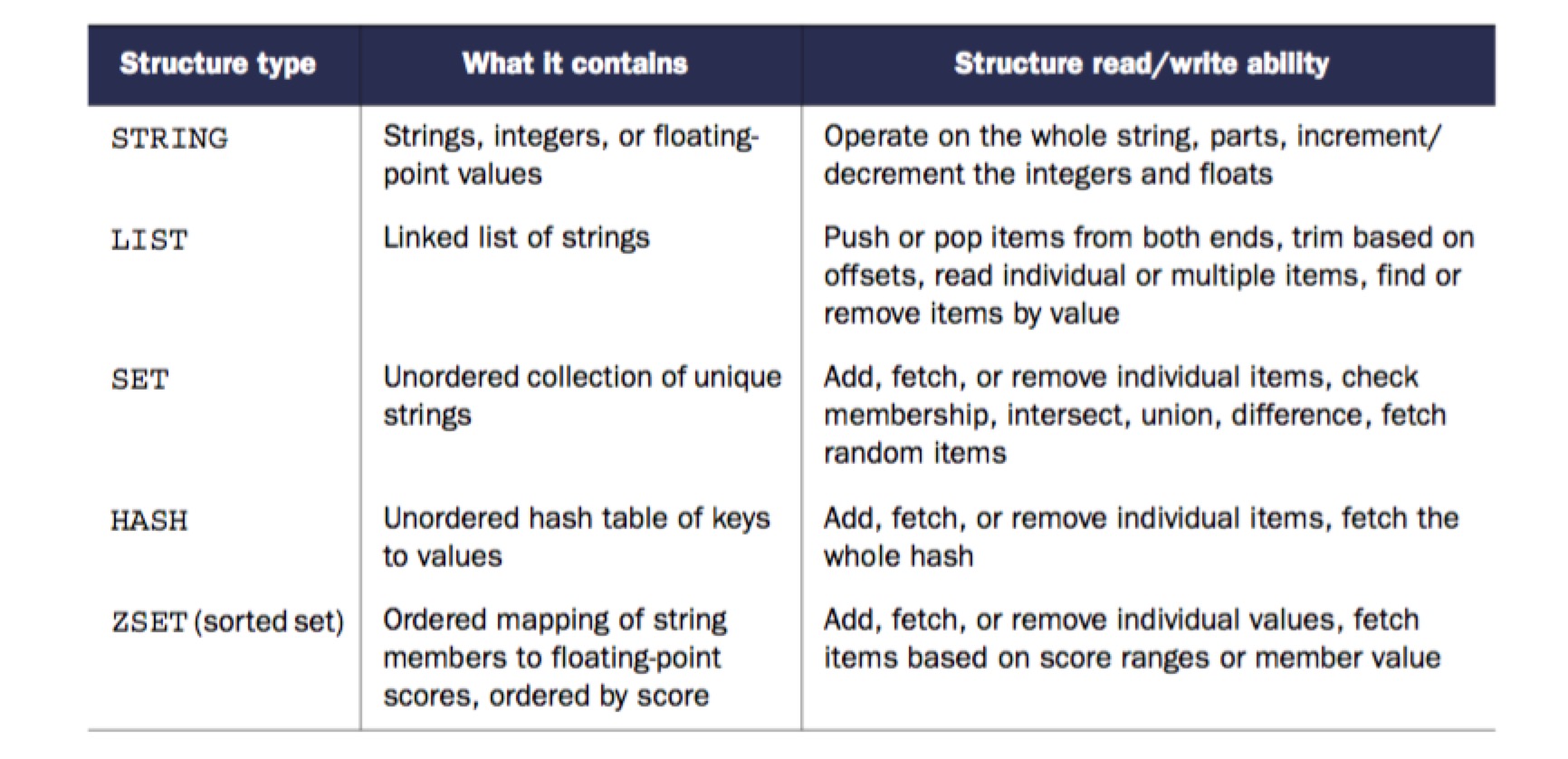
Redis 的常见数据结构有:
- STRING
- LIST
- SET
- HASH
- ZSET
- Bitmaps
- HyperLogLog
- GEO
注意:基本类型只有:string, list, set, hash, zset,bitmaps & hyperloglog 是基于 string 实现的,GEO 是基于 zset 实现的。
每种数据结构都有多种内部编码实现。可以使用 object encoding key 来查看 key 的内部编码。

ziplist 等压缩编码可以减少内存消耗,但是操作这些数据会消耗更多 CPU,需要做权衡。
Strings in Redis
redis 的 string 可以存储:
- 字节串(byte string)
- 整数
- 浮点数(双精度)
对 string 的操作命令:



Bitmaps
Bitmaps 这个”数据结构”可以实现对位的操作。加引号是因为,严格来说,bitmaps 不能算一种数据结构,实际上它就是 string,只不过可以对 string 进行位操作。可以把 Bitmaps 想象成一个以 bit 为单位的数组。
可以通过 bitmaps 来实现布隆过滤器 bloom filter 合理使用位操作能有效的提高内存使用率 & 开发效率
Lists in Redis
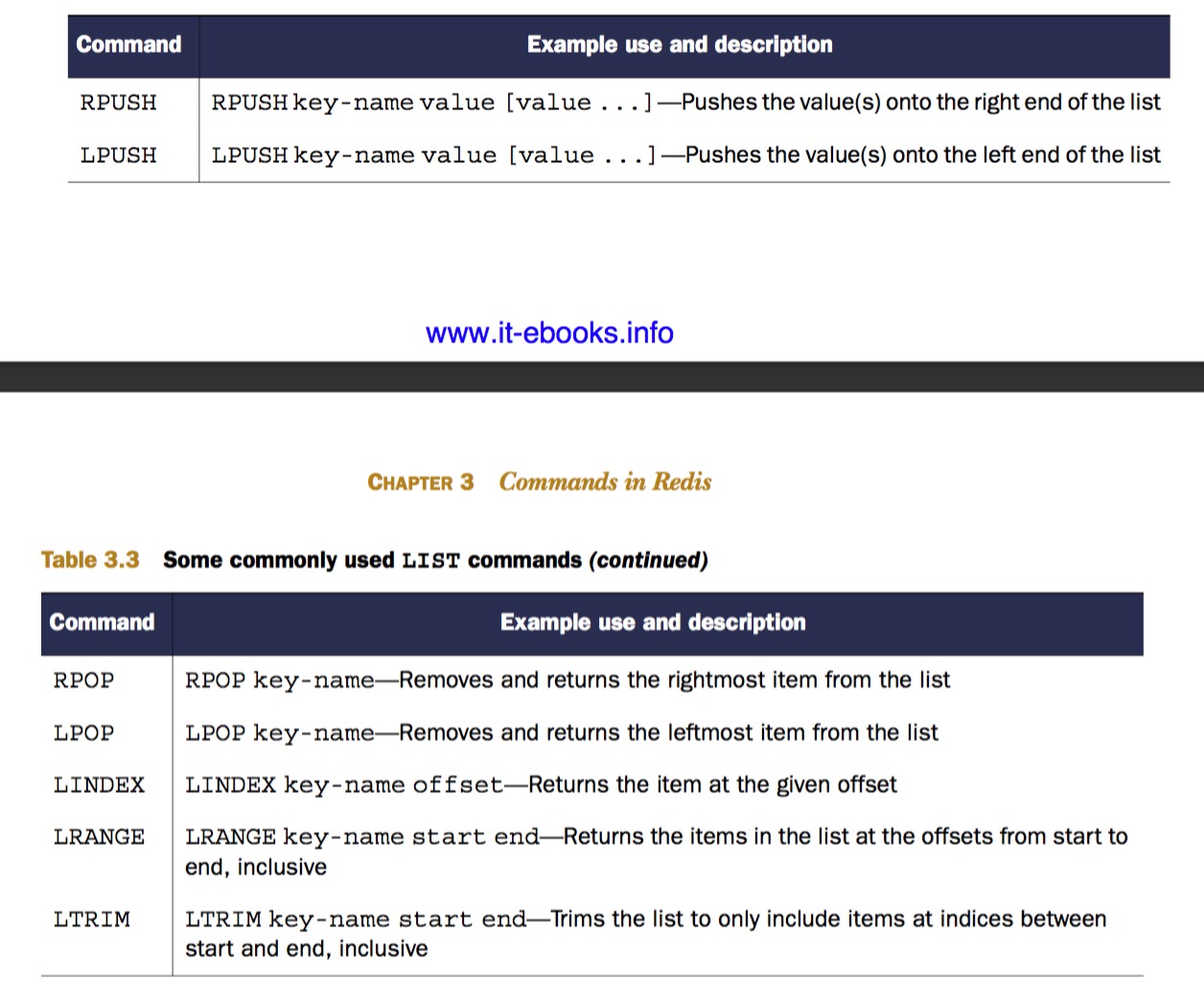

通过 list 可实现栈 & 队列,来达到实现一个简单 pub/sub(message queues, task queues) 系统的需求:
- FIFO queues(队列): RPUSH & BLPOP
- FILO queues(栈): RPUSH & BRPOP
Sets in Redis
Redis SETs 通过 hash table 存储唯一性数据
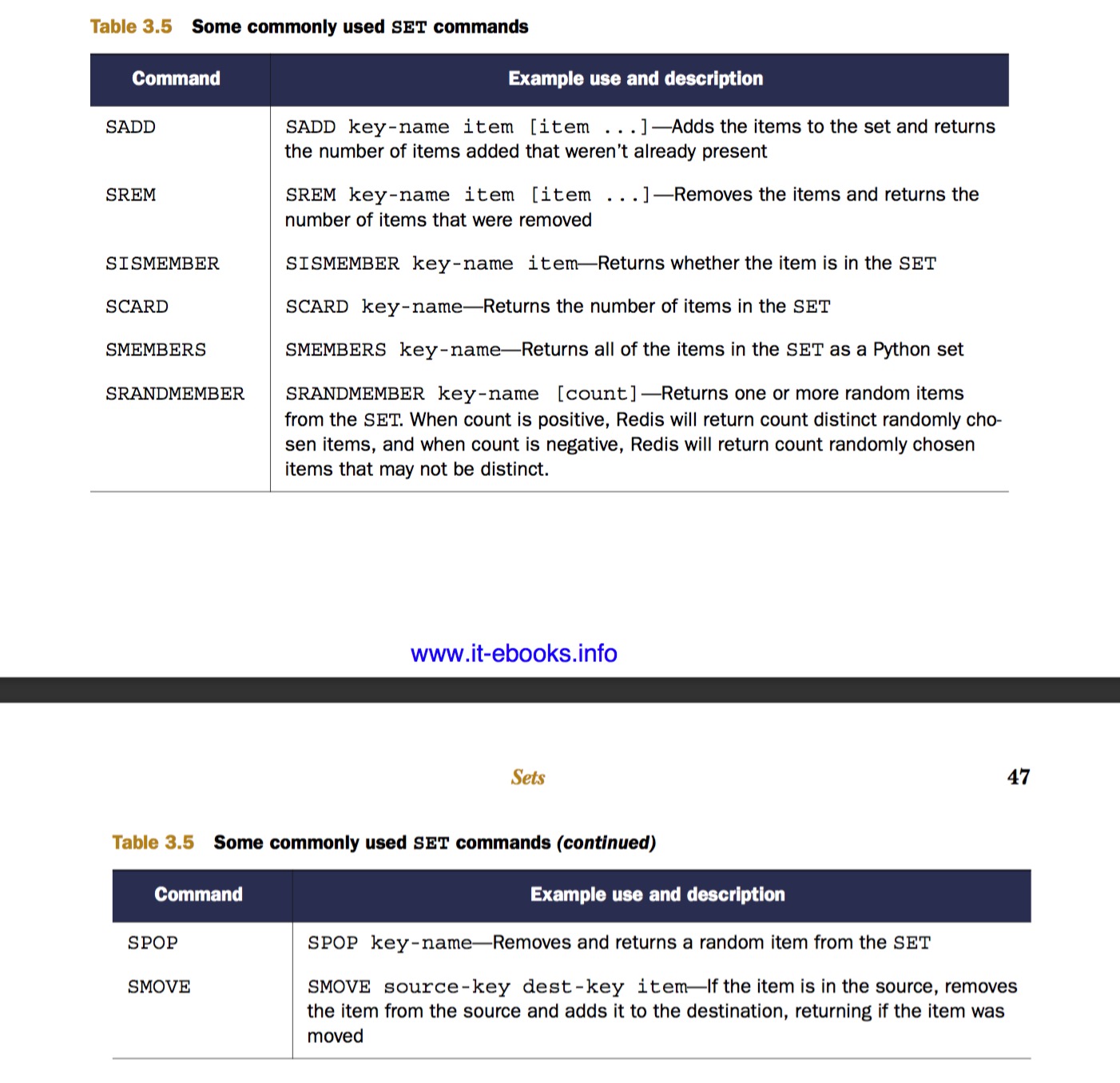
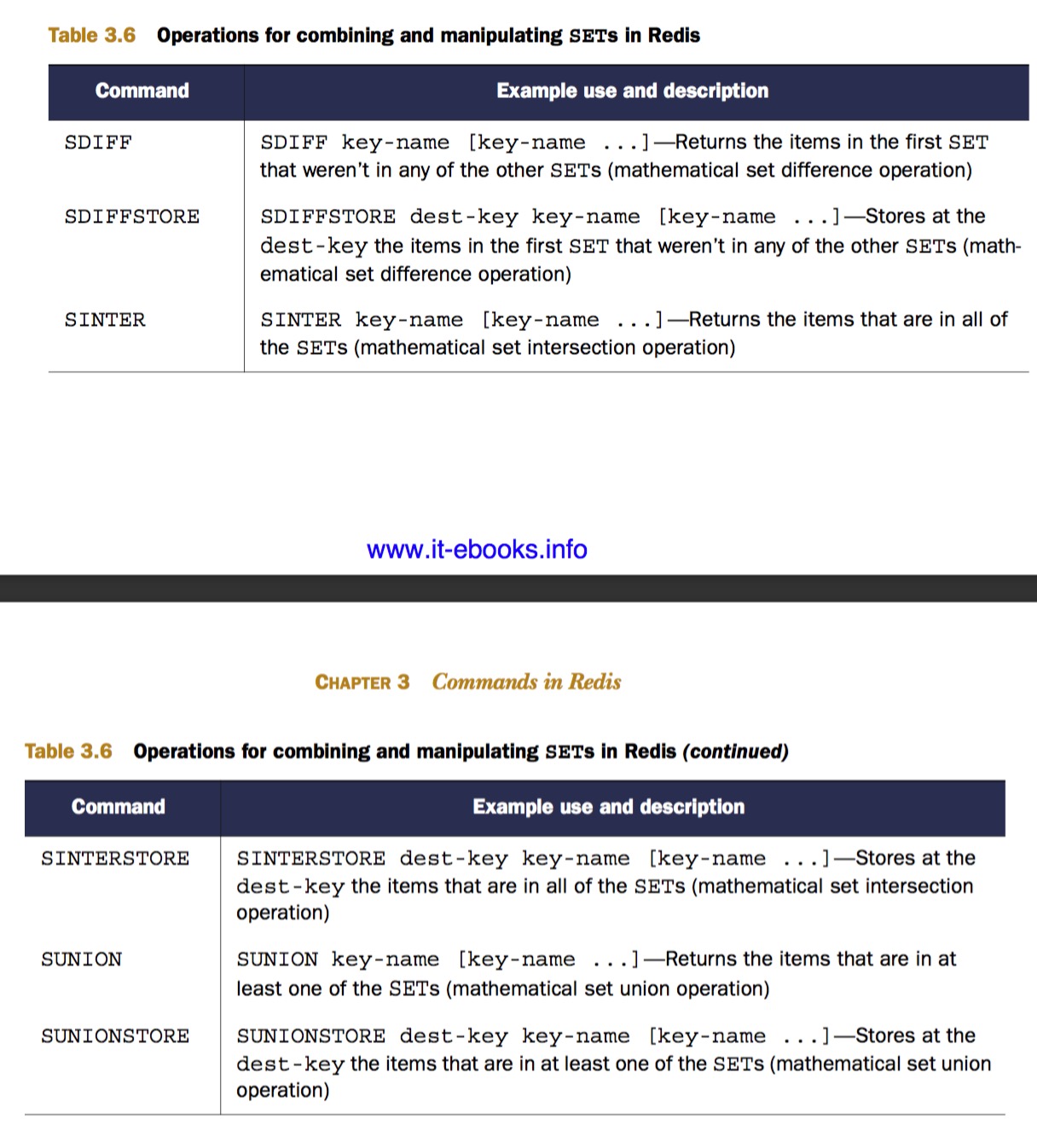
上面这些命令是并集运算,交集运算,差集运算这三个集合操作的返回结果版本 & 存储结果版本。
Hashes in Redis
Hash 适合将一些相关的数据存储在一个数据中。可以把 Hash 理解成关系型数据库中的行或文档数据库中的文档。



Sorted sets in Redis
key 是 unique, value 是一个 floating-point numbers。


Redis 的一些操作可以同时处理 SETs & ZSETs,如 zinterstore 等,其中的一个重要参数 aggregate 可以配置:
- max
- min
- sum
zset encoding:
- ziplist
- skiplist + hashtable
SkipList + HashTable
hashtable 维护 key 到 score 的对应关系,当执行
- ZREM key member [member …]
- ZINCRBY key increment member
- zscore 等操作时,可通过 hashtable 快捷的处理
skiplist 维护 score 到 key 的关系 & range query:
- zrevrange
- zrevrank

Redis 中的 skiplist 跟经典的 skiplist 相比,有如下不同:
- 分数(score)允许重复,即 skiplist 的 key 允许重复。这在最开始介绍的经典skiplist中是不允许的。
- 在比较时,不仅比较分数(相当于skiplist 的 key),还比较数据本身。在 Redis 的 skiplist 实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
- 第 1 层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在 skiplist 中可以很方便地计算出每个元素的排名(rank)。
HyperLogLog
Redis HyperLogLog 是用来做基数(不重复元素)统计的算法。
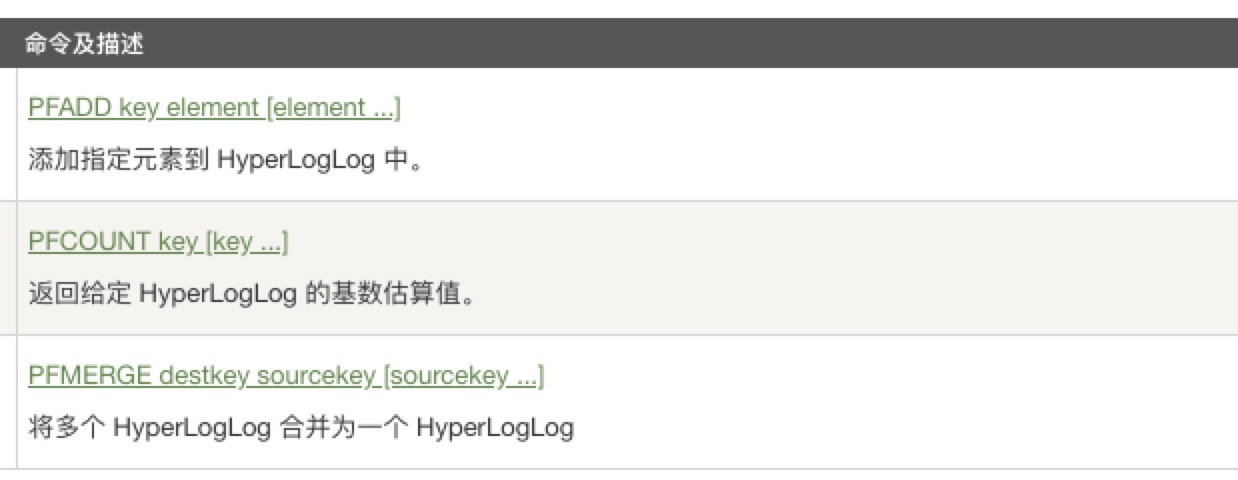
- 优点: 在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
- 缺点:
- HyperLogLog 只会根据输入元素来计算基数,不会储存输入元素本身,所以它不能像集合那样,返回输入的各个元素。
- 虽然内存占用量小,但是存在计算误差
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
GEO
GEO(地理位置信息),通过该数据结构,可以实现附近位置、摇一摇等基于地理位置信息的功能。
Expiring keys
过期时间只能为整个 key 设置,无法针对 key 中的单个元素设置。

Redis 的删除策略有:
- 惰性删除:
- master 每次处理读取命令时,检查 key 是否超时,如超时则执行 del & 同步 del 命令到 slaves & 返回 client null。
- slave 只会在收到 master del 命令时才会删除超时 key,但是对 slave 做 get 时,如果检查到 key 过期,则不会返回该数据。
- 定时删除:redis 内部定时循环采样一定数量的 key,发现过期则 del & 同步给 slaves。
Transactions
Redis 有 5 个命令来帮助我门操作多个 keys 的过程中不被打断:MULTI, EXEC, WATCH, UNWATCH, and DISCARD。
使用事务的好处:
- prevent data corruption
- Improving performance
Rollback
Redis 的事务不支持 rollback,如果 transaction 中的某个中间操作出错,前面已执行的命令是无法自动 rollback 的(需要开发人员手动干预),后面的命令还会继续执行。 这是因为:
- 一般来说,redis 的异常大部分都是语法异常,这种异常在 development 阶段基本都能发现 & fixed
- redis 的核心目的是为了 faster
所以,redis 选择牺牲 transaction 的 rollback。
MULTI & EXEC
redis client 调用 pipeline() 会创建事务。client lib 会自动使用 Multi & EXEC 包裹起用户输入的多个命令。事务保证了在执行的过程中是原子性的,多个命令执行间隙不会被别的事务干扰。
Client lib 会队列化存储事务包含的多个命令,在调用 EXEC 时,一次性将 Multi 命令、事务中的所有操作命令、EXEC 命令发给 redis server,这样做通过优化网络调用次数显著的提高效率。
由于在调用 EXEC 前,不会执行任何实质性操作,所以事务中后一个命令的执行不能依赖前面命令的执行结果。
WATCH & UNWATCH & DISCARD
除了 multi & exec 命令外,还经常用到 watch。在使用 watch 对 key 进行监听后,exec 执行前,如果有别的事务修改了 key 的值,当执行 exec 时,事务将返回失败。
在 multi 前,可以调用 unwatch,取消监听,multi 后,就只能调用 discard 来取消监听了。

- 在写入数据时,关系型数据库中经常对访问的数据进行加锁,直到事务 commit or rollback。过程中如果别的 client 对被加锁的数据执行写入,会阻塞到直到第一个线程执行结束。这是pessimistic locking 悲观锁的实现,容易引起阻塞,导致整体性能降低。
- Redis 为了减少 client 的阻塞等待,在 watch 时并没有加锁,只是在数据被其他 client 抢先修改后,返回失败(让 client 自己选择 retry or quit),而不是阻止其他 client 对数据进行修改,这是 optimistic locking 乐观锁的思想。
乐观锁 vs 悲观锁:
- 乐观锁:假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
- 问题:并发修改频繁时,失败的概率很大,经常需要重试
- 适用场景:读多写少业务
- 悲观锁:“先取锁再访问”的保守策略,为数据处理的安全提供了保证。
- 问题:长事务中,锁占用时间过长。处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会
- 适用场景:写多的业务
PIPELINE
事务底层也使用了 pipeline 来优化性能。某些情况下,我们不需要使用事务的原子性,而仅仅希望利用 pipeline 减少网络通讯次数来提高性能。
MGET, MSET, HMGET, HMSET, RPUSH/LPUSH, SADD, ZADD, 等命令简化了那些需要重复执行相同命令的操作,大大提高了性能。
如果想一次性执行不同命令,则需要使用 pipeline 了。只需要在调用 pipeline 时,传入事务标记为 false,client 会像事务那样收集起所有的命令,一次性发送到 redis server,但不会用 multi & exec 包裹命令。
Pipeline 和 transaction 一样,由于在真正发起调用前,不会执行任何实质性操作,所以事务中后一个命令的执行不能依赖前面命令的执行结果。
Persistence

两种持久化方案:
- snapshots
- aof
Snapshots
获得存储在内存里面的数据在某个时间点上的副本(point-in-time dump),创建 RDB 文件到磁盘中。
注意:在新的 snapshots 创建之前,如果 redis 崩溃,将导致丢失最近一次 snapshots 之后的写入的数据。如果不能接受数据丢失,需要使用 AOF。
创建 snapshots 的方式:
- 手动触发 * SAVE 命令:阻塞式的创建快照。save 只有在 redis 内存不够的情况下才会使用,其他情况不推荐用 * BGSAVE 命令:对 save 做的优化,redis 会 fork 出一个子进程,该子进程负责将快照写入磁盘,父进程继续负责执行命令
- 自动触发:配置 save 选项,如:save 60 1000,redis 在满足 60s 内存在 1000 次修改时,自动触发 bgsave(如配置了多个 save 项,只要有一个满足就触发 bgsave)
- slave 连接到 master 时,slave 会发送 SYNC command,如果 master 没有正在执行/刚执行过,master 将执行 bgsave,将执行完的 snapshot 文件发给 slave
- redis 收到 shutdown 命令时/term 信号时,会阻塞式的 save 数据
当 redis 内存中的数据量很大导致可用内存不多时,fork 出线程去执行 bgsave 可能会:
- 引起系统 pause 一段时间
- 使用 virtual memory
fork 调用的 copy-on-write 机制是基于操作系统页这个单位的,也就是只有有写入的脏页会被复制
rdb 优点:
- rdb 体积小,适合用于备份,全量复制
- redis 家在 rdb 的速度远快于 aof
rdb 缺点:
- rdb 没法做到实时持久化,因为 bgsave fork 子进程是重量级操作
Append-only file
将写命令写到 AOF 文件的末尾,以此来记录数据的变化。因此,只要从头执行一遍 AOF 的所有写命令,就能恢复所有数据。
appendfsync 的同步选项:
- always: Every write command to Redis results in a write to disk. 不推荐
- benefit: 数据不会丢失
- drawback: 性能很差
- everysec: Once per second, explicitly syncs write commands to disk. 推荐
- benefit: 最多只丢失 1s 的数据,同时性能不受影响
- no: Lets the operating system control syncing to disk. 不推荐
- drawbacks: 对丢失的数据量不可控
- exec 指令将会触发事务中所有的操作被写入 AOF 文件
AOF 优点:
- 可以针对数据的不同安全程度,设置不同的值 AOF 缺点:
- 文件体积过大,从头执行一遍 AOF 写命令,太费时
可以定期 BGREWRITEAOF 移除 AOF 中的冗余命令来,达到压缩 AOF 的目的。
BGREWRITEAOF
BGREWRITEAOF 如何达到优化体积的目的:
- 超时的数据不在写入文件
- 使用进程内的数据直接生成,新的 aof 只保留最终数据
- 多条命令可合并成一条
BGREWRITEAOF 触发方式:
- 手动触发 BGREWRITEAOF
- 和配置 save 选项来自动触发 bgsave 一样,自动触发 bgrewriteaof:
- auto-aof-rewrite-percentage
- auto-aof-rewrite-min-size
BGREWRITEAOF 和 BGSAVE 类似,都是通过创建子进程来执行重写操作,所以都有因为创建子进程而引起的内存占用过大问题。
根据业务需求,这两种持久化方案可以独立使用,也可以结合使用。当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能以及最大的内存使用量。
利弊
缓存场景,数据存放在数据库,缓存在 redis 中,开启 persistence:
- 优点: redis 挂了再重启,内存里能够快速恢复热数据,不会瞬时将压力压到数据库上,没有 cache 预热的过程
- 缺点: redis 挂了的过程中,如果数据库中有数据的修改,可能导致 redis 重启后,数据库与 redis 的数据不一致 因此,只读场景或者允许不一致的业务场景,可以充分利用 persistence。
Replication
持久化可以保证数据保存在本地的磁盘上,除此之外,通过 replication 将数据备份到不同的机器上去,又为数据提供了一层保护。Replication 带来的好处:
- master 出现故障时,能 failover,保证数据的安全性
- 更高的读性能
Slaveof
redis server 启动时,指定 slaveof host port,即会去连接该 master 服务器。运行过程中:
- slaveof no one: 停止 follow master
- slaveof host port: follow 一个新的 master
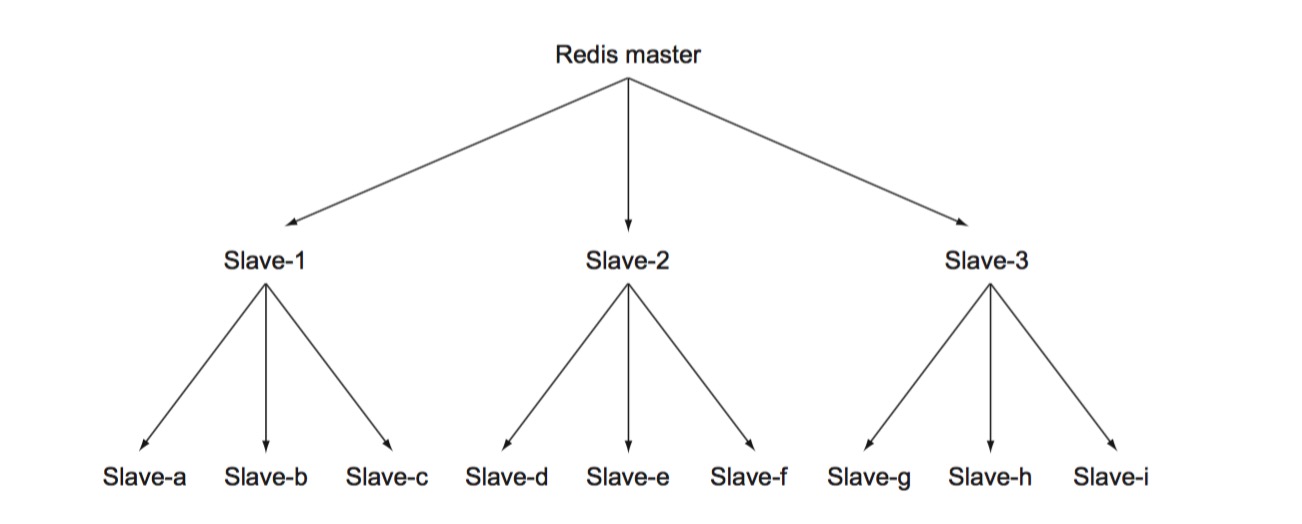
Master/slave chains
当 master 挂载过多的 slaves 时,如果遇到大量 slaves 请求全量复制的场景,会导致 master 节点严重的网络阻塞甚至阻断写请求。这时可以配置 slave 拥有自己的 slaves,从而形成 Master/slave chains,来优化性能,规避复制风暴。
Data sync
同步数据过程分为:
- 全量复制:初次复制场景,数据量大时,对主从节点和网络有很大压力
- 异步复制:主从服务架构稳定后,master 执行完写请求后,异步发送给 slaves 执行
- 部分复制:主从复制过程中如果出现网络闪断等原因,网络恢复后,主节点补发丢失数据
redis 中用于同步的命令是 psync,其中的关键参数是 offset。offset 是复制偏移量。参与复制的 master, slaves 都会维护自身的 offset,通过比较 offset,就能知道主从数据是否一致,以及相差多少。
全量复制

全量复制的开销大:
- 生成 rdb 文件的时间
- 网络传输 rdb 的时间
- slave 清空本地历史 rdb 的时间
- slave 加载 rdb 的时间
所以,除了在 slave 第一次连接上 master 时使用全量复制,其他时候都建议使用部分复制。
异步复制
master-slaves async 复制方式
写命令的发送是异步的。master 处理完写命令后直接返回 client success,不会等待 slave 的复制完成。所以数据复制是有延迟的,可能造成短暂的数据不一致性问题,读 slave 读不到最新数据。
部分复制
master 写数据时,会:
- 把命令发给 slaves
- 把命令写入复制积压缓冲区
当网络闪断命令丢失发生后,网络恢复正常时,master 根据 offset 从复制积压缓冲区读取需要补发的命令给 slaves。复制积压区默认 1MB,如果该区域没有 slave 请求的 offset,则部分复制退化为全量复制。
slaves 每隔 1s 发送 replconf ack {offset} 命令给 master,上报自身的 offset,并实现 heartbeat。
REDIS DOESN’T SUPPORT MASTER-MASTER REPLICATION
Sentinel
有了 Master-slaves 架构后,我们就需要考虑如何自动化的管理整个集群,这时 Redis Sentinel 出现了。 Sentinel 被设计成为类似于 chubby,zookeeper 一类的独立于数据节点的协调组件,本质上是一个特殊的 redis server,它可以帮助我们实现 redis 的 HA,自动完成 fault discovery(故障发现) & failover(故障转移)。
每个 Sentinel 都会维护 redis servers(master & slaves) 和别的 sentinels 的状态信息。同时对别的 sentinels & redis master & redis slaves 定期的发送 ping 命令来进行监控:
- 当有别的 sentinel 下线时:
- 当有 redis master 下线时:选举某个 slave 当 master,别的 slaves follow 新的 master
- 当有 redis slave 下线时:
Sentinel 自身的 HA
我们使用 sentinel 来维护 redis server 的 ha,sentinel 一般也需要形成 cluster,因为:
- sentinel 本身也需要做到 ha
- 对节点故障的判断是由 quorum sentinel 决定的,防止误判
对于 sentinels 的部署,我们建议:
- 不要部署在同一台物理机/机架/机房上
- 至少 3 个且为奇数个 sentinels
Quorum
quorum 的作用:
- 至少要有 quorum 个 sentinels 参与 sentinel leader election 过程
- 至少要有 quorum 个 sentinels 认可 master 宕机
quorum 的值可以选择,一般推荐 quorum >= n/2 + 1。
可以参考 Zookeeper 中 quorum 的作用
Sentinel leader election
Sentinel 使用 Raft 算法来进行 sentinel cluster 的 leader election。
Master failover
- sentinel 每隔 1s ping redis master,如果发现 timeout 后还没响应,则认为 master 主观下线
- 发现 master 不可用的 sentinel 和别的 sentinels 交互,当 quorum 个 sentinels 都认为 master 不可用时,标记 master 客观下线(防止误判)
- 选举出 sentinel leader
- sentinel leader 进行 failover 工作,选举出新的 redis master
- 过滤不可达的 slaves
- 选择 slave-priority 最高的 slave
- 选择 offset 最大的
- 选择 runid 最小的
- 将新的 master 通知所有的 redis servers & redis clients
- redis slaves follow 新的 master
- client 更新本地的 master & slaves 配置信息
Redis Cluster
sentinel 支持的 replication 是解决:
- ha
- 读性能
但是当数据量很大时,我们需要从 partition 的角度来优化 redis。partition 的方式有:
- 客户端分区,client 控制 partition 逻辑,但是需要 client 自己处理数据路由、故障转移等问题
- 统一的 redis cluster 来控制 partition
redis 是采用由 redis cluster 来计算 partition 的方式的。具体来说,redis cluster 采用 Consistent hashing with virtual nodes(虚拟槽 hash 分区)。
现代的 client lib(如 JedisCluster)已经可以缓存 slot -> node 的对应关系了:
- 缓存信息无误时,client 根据缓存可以为 key 找到正确的 node,从而正常操作 key,效率高
- 缓存信息有误时
- redis server 判断 key 不在本机上,返回 MOVED 指令 & 告诉 client 重定向到哪个 server,自身不负责转发
- client 拿到 MOVED 指令后,更新 slot -> node 的缓存
需要注意的问题:
- mset, mget 只支持具有相同 slot 的 key 的操作
- 只支持多个 key 在同一个节点的事务
- key 是 partition 的最小粒度
partition 详情可参考 # Partition 这篇文章
Redis 内存分析
一般推荐 redis server 最多占用可分配给 redis server 的最大内存的 50–65%,留 30–45% 来执行 BGSAVE 等操作。
组成
- 自身内存
- 对象内存
- 缓冲内存
- 客户端缓冲区
- 复制积压缓冲区
- AOF 缓冲区
- 内存碎片
内存溢出
内存优化
如何节省内存空间
缩短 key 长度 缩短 value 长度:优化 bitmaps hyperloglog
不要让你的 Redis 所在机器物理内存使用超过实际内存总量的 3/5
如何提高性能
大对象拆分成小对象 hgetall 改为 hmget 等 禁用 keys, sort 等命令
Redis Streaming
Streaming 是 redis 5.* 提供的功能,目前这块还没深入了解。
Redis 管理
常用命令
redis-cli 管理:
- info: 显示 redis server 的基本信息
- info clients: 查看 clients 的汇总信息
- client list: 精准分析每个 client
- info commandstats: 统计命令的执行次数 & 执行耗时
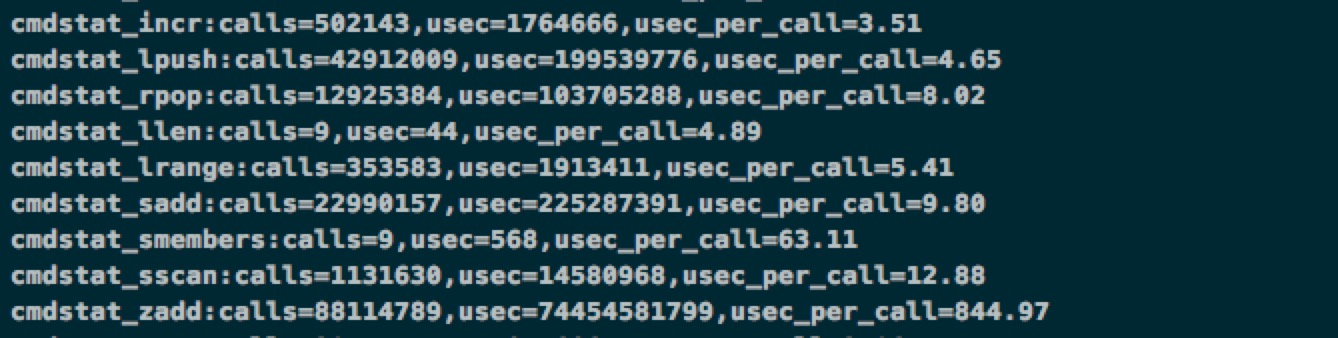
redis-cli -h {ip} -p {port} –stat: 获取 redis 当前使用情况 redis-benchmark:压测 cat /proc/{redis_process_id}/smaps | grep Swap: 查看 redis 是否有被执行 swap 内存交换,如这个值过高,则有大量的数据被交换到硬盘,严重影响 redis 性能。
重要配置
client-input-buffer-limit: 客户端输入缓冲区 client-output-buffer-limit: 客户端输出缓冲区 maxclients: 最大支持的 client 连接数 timeout: 连接的最大时间,超过之后,连接就被关闭
故障分析
客户端无法从连接池获取到连接:
- 连接池设置过小,供不应求
- 客户端用完连接资源后,忘记释放
- 发起慢查询,导致连接无法及时释放
- redis 服务端由于有问题,导致响应客户端较慢
客户端调用 redis server 时,连接超时:
- 连接超时设置的很短
- redis server 发生阻塞
- client 于 server 的网络出现异常
使用场景
Cache
参见 #Cache Design.md 一文
Distributed Lock
编程中有各种各样的锁,操作系统锁,数据库锁,编程语言级别的锁。 这里我们了解一下 redis 构成的锁,这个锁不是给同一进程中的不同线程使用,不是给同一机器上的不同进程使用,而是给不同机器不同进程使用的,全局可见的锁,分布式锁。
setnx(nx=not exist) 只会在 key 不存在的情况下设 value,如果 key 已经存在,返回 0,可以利用这个特性来实现 redis lock。
也可以使用 zookeeper 临时节点来构建分布式锁
Counting semaphores
Counting semaphores 计数信号量也是一种锁,它限制一项资源最多被多少进程访问。锁可以看成是只允许一个进程访问。和锁一样,Counting semaphores 都需要被获取 & 释放。
可以使用 zset 来实现 Counting semaphores
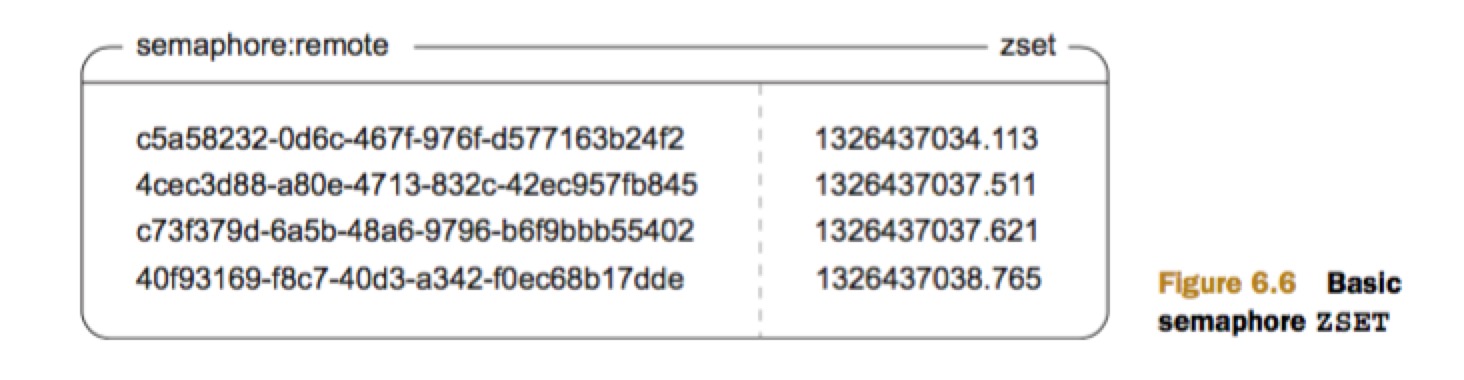
key 为 client id,value 为 timestamp。但是这个实现存在一个问题,由于系统时钟的不同步,可能导致
- 系统时钟慢的 client 偷走时钟快的 client 的信号量
- 有些 client 永远获取不到信号量 所以这个实现是不公平的。
Fair semaphores
由于信号量的不公平是由于系统时间漂移导致的,所以这里可以把时间换成一种全局自增数来实现。
Message queue
Pub / Sub
 Redis 实现的 pub/sub 是非常简单的,采用广播模式。存在大量的问题,仅能作为简单使用。
注意:redis 不会对 messages 进行持久化,所以新的 consumer 无法收到 channel 之前的 messages。
Redis 实现的 pub/sub 是非常简单的,采用广播模式。存在大量的问题,仅能作为简单使用。
注意:redis 不会对 messages 进行持久化,所以新的 consumer 无法收到 channel 之前的 messages。
List
FIFO queues(队列): RPUSH & BLPOP
Delay queue
通过 Sorted Set 实现,score 是 expired time
不论是 pub/sub 还是 list,redis 都只能实现简单的 mq 功能,完善的还需要使用 kafka,rabbitmq 等。
Bloom filter
可以通过 bitmaps 来实现布隆过滤器 bloom filter
References
redis cluster tutorial redis cluster Redis内存使用优化与存储 Redis的内存优化 HyperLogLogs in Redis Skiplist Ziplist Quicklist