本文部分参考自:《ZooKeeper: Distributed process coordination》 Apache ZooKeeper, a distributed coordination service for distributed systems. Zookeeper 最初是由 Yahoo 公司开发的,主要用于支持 robust distributed system,后期贡献给了 Apache 基金会。不像单体应用,在分布式系统中各个节点间的 Coordinating 是困难的。Zookeeper 正是为了解决分布式系统的协调工作(coordinating task),它通过提供通用的功能,让 application developers 能专注于自身的业务功能,而不用过多的关注分布式系统的协调。
Zookeeper 名字的来源也非常的有趣且到位。分布式系统可以比做 zoo,里面有各种各样不同的应用(animals),而 zookeeper 的目的就是保证各个应用间的可控和有序。
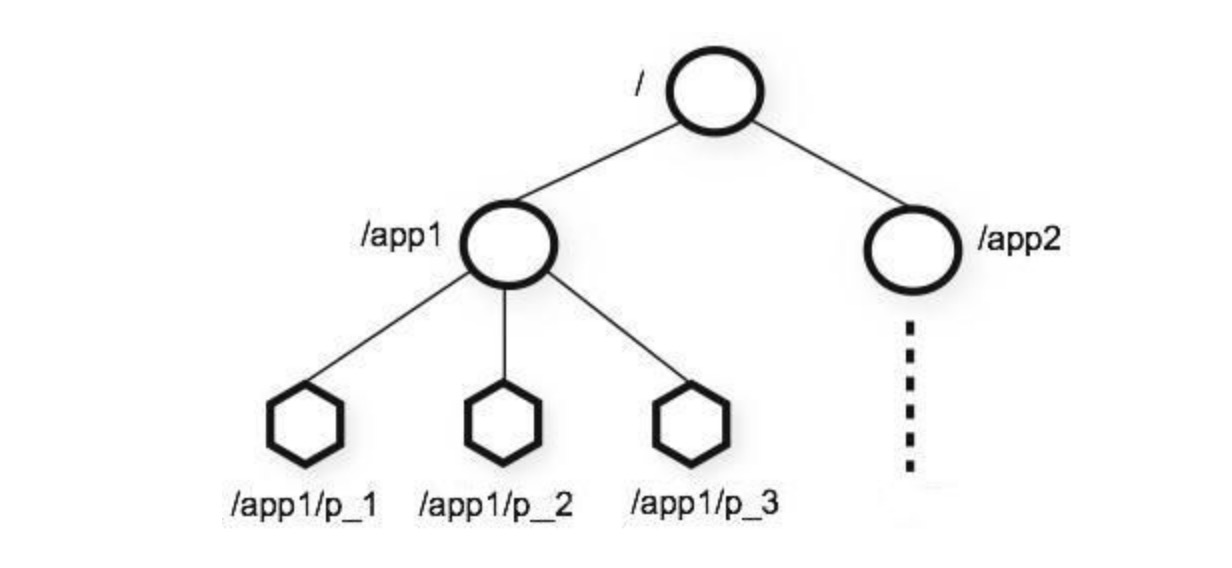
ZooKeeper 某种程度上可以理解为 distributed file system。顶层是一个根节点 /,根节点上有 zNodes,zNode 既可以保存 binary data,又可以当成一个 directory 来持有更多的 zNodes。 并通过暴露一些简单的 client API,来让开发人员实现通用的协调任务,例如:主节点选举,管理组内成员关系,管理员数据等。
需要注意的是,zk 并不为我们直接实现 leader election, distributed lock 等功能,我们需要通过 zk 暴露的简单的 api 来自己实现。好在现在已经有一些开源库实现了这些功能,如 Curator
What ZooKeeper Doesn’t Do
虽然 zk 某种程度上类似 Distributed file system, Message Queue
Distributed file system: Zookeeper 不适合作为 large data storage Message Queue:
Building Distributed Systems with ZooKeeper
分布式系统的概念这里不提了。
分布式系统中的应用进程可以通过两种方式进行通信:
- 直接通过网络交换信息
- 读写某些共享存储
zk 通过 shared storage model(共享存储模型)来实现各个应用间的协作,当然,对于共享存储本身,需要进程和存储间进行网络交换。
Use Cases
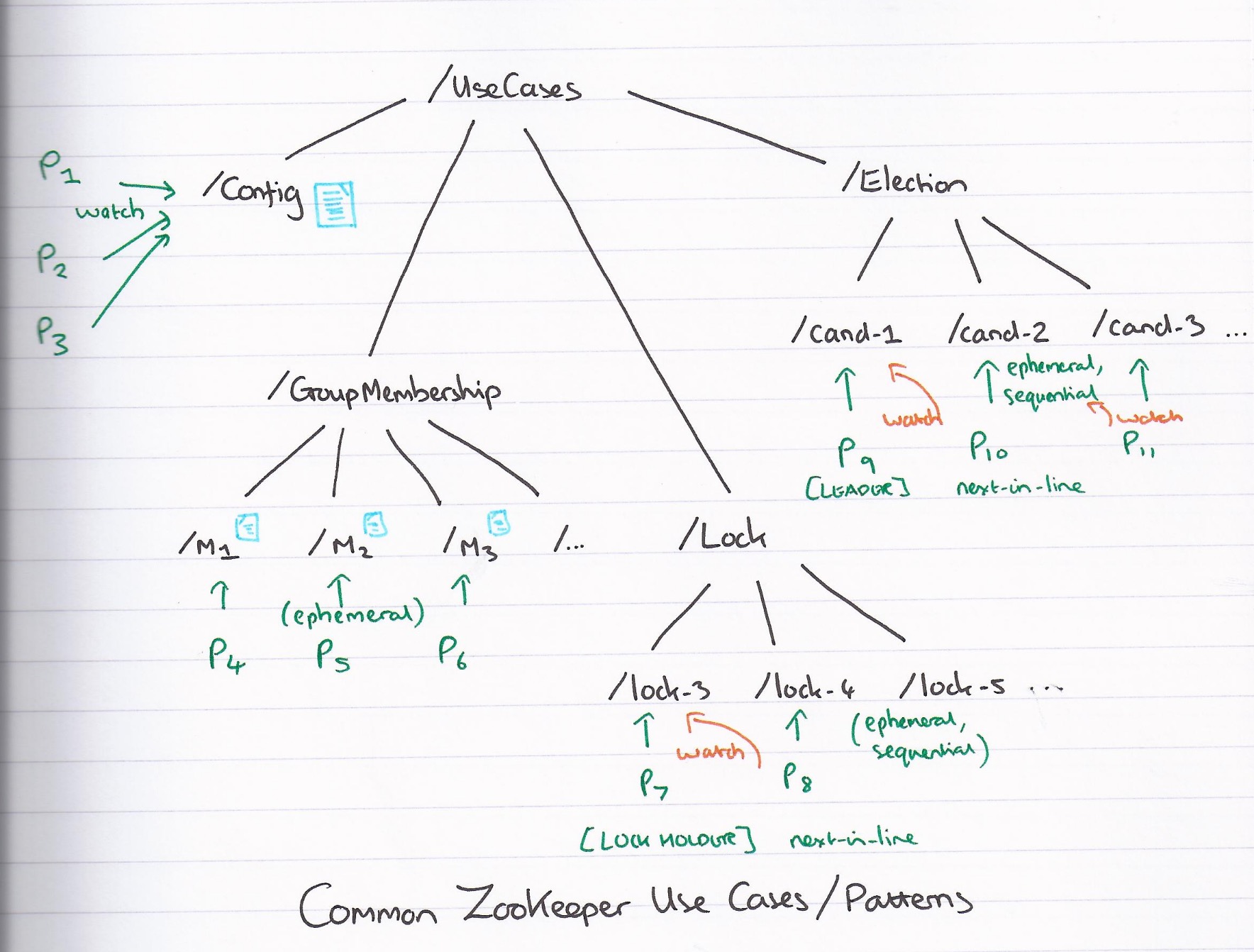
naming service: 命名服务,典型场景是分布式服务中的服务地址列表
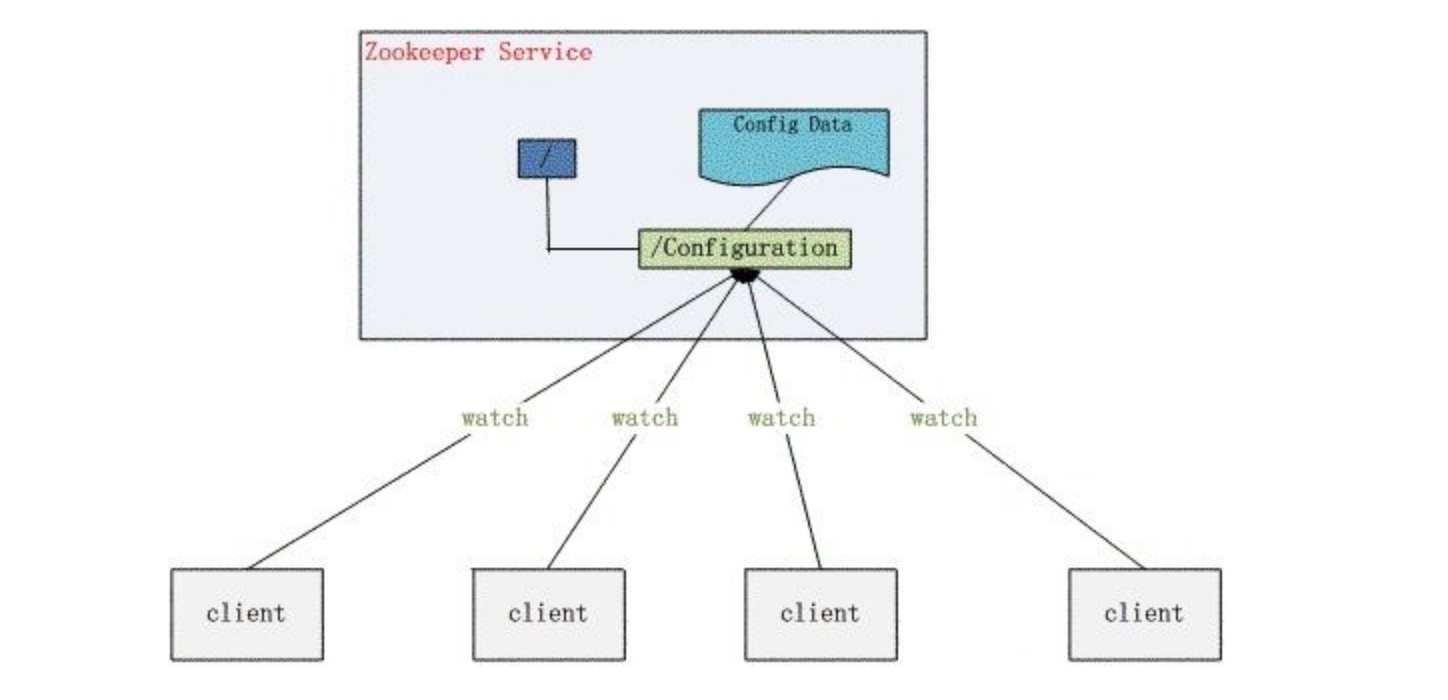
configuration management: 数据发布与订阅(配置中心)
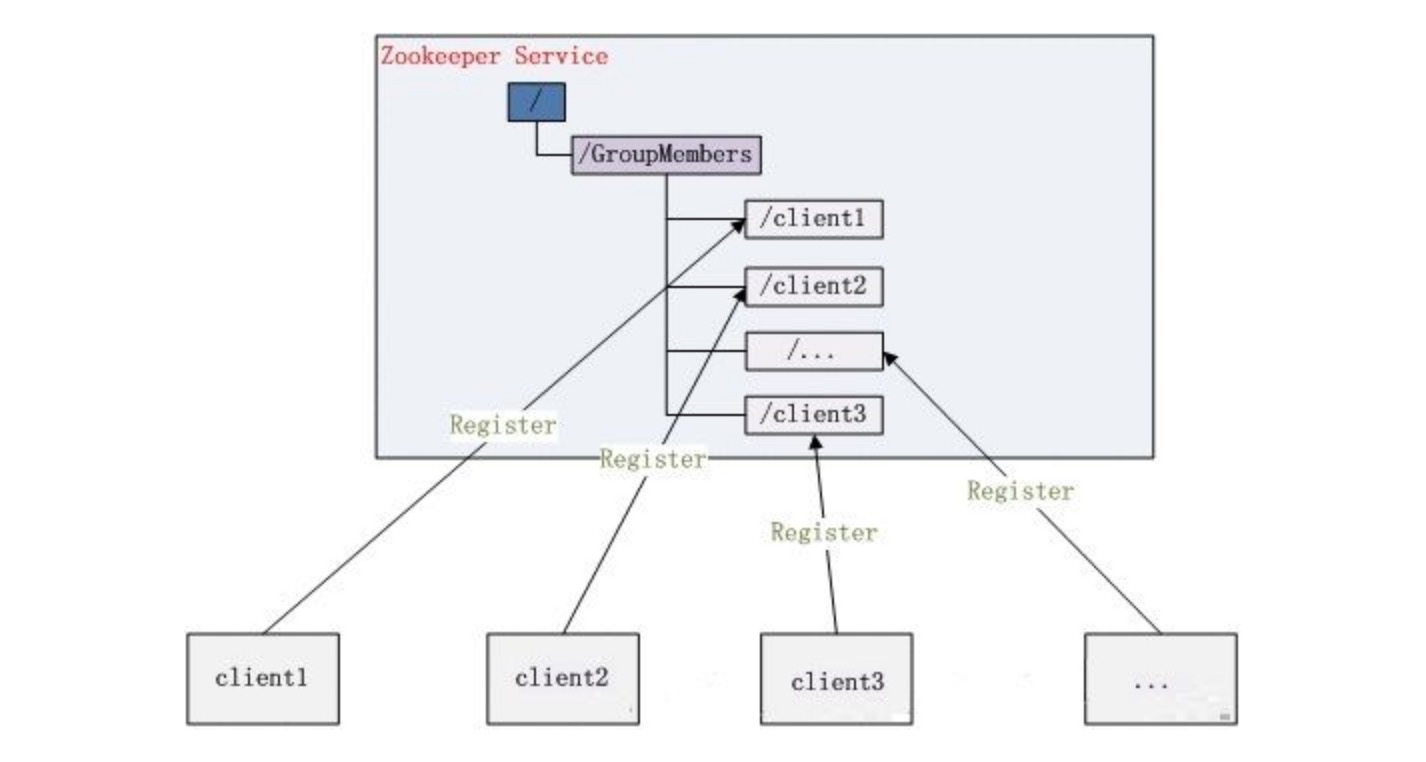
group membership
leader election distributed lock service discovery resource allocation high priority notifications
Znode
Zookeeper 操作 & 维护节点树,这些节点被称为 znode,类似于文件系统的层级树状结构。
API for Znode
zk 暴露了一些 api 来操作 znode:
- create /path data: Creates a znode named with /path and containing data
- delete /path: Deletes the znode /path
- exists /path: Checks whether /path exists
- setData /path data: Sets the data of znode /path to data
- getData /path: Returns the data in /path
- getChildren /path: Returns the list of children under /path
Different Modes for Znodes
和普通的 distributed file system 不同的是,ZooKeeper 支持不同种类的 zNodes。
Persistent and ephemeral znodes
从节点持久度上,zk 的 node 可分为两种:
- Persistent znodes 持久节点
- Ephemeral znodes 临时节点:目前临时节点不能创建子节点
delete node:
- 持久节点只能显示调用 delete 方法来删除
- 临时节点可通过:
- 当创建该节点的 client session 关闭与 zk server 的连接,或与 zk server 的连接超时,被 zk server 自动删除
- zk client 主动删除
Sequential
znode 还可被设置为 sequential node(有序节点)。 sequential znode 被 zk 分配唯一的,单调自增的 int 值,通过这个自增值,也可以看出节点的创建顺序。
组合起来后,zk 共有四种 znode:persistent, ephemeral, persistent_sequential, and ephemeral_sequential.
Ephemeral znodes 的应用场景包括:discovery of hosts sequential znode 的应用场景包括:leader election, distributed lock
Versions
每个 znode 都有一个版本号,它随着每次的 change 而自增。但是 znode 节点被 delete & recreated 后,其版本号将会被 reset 回 0。
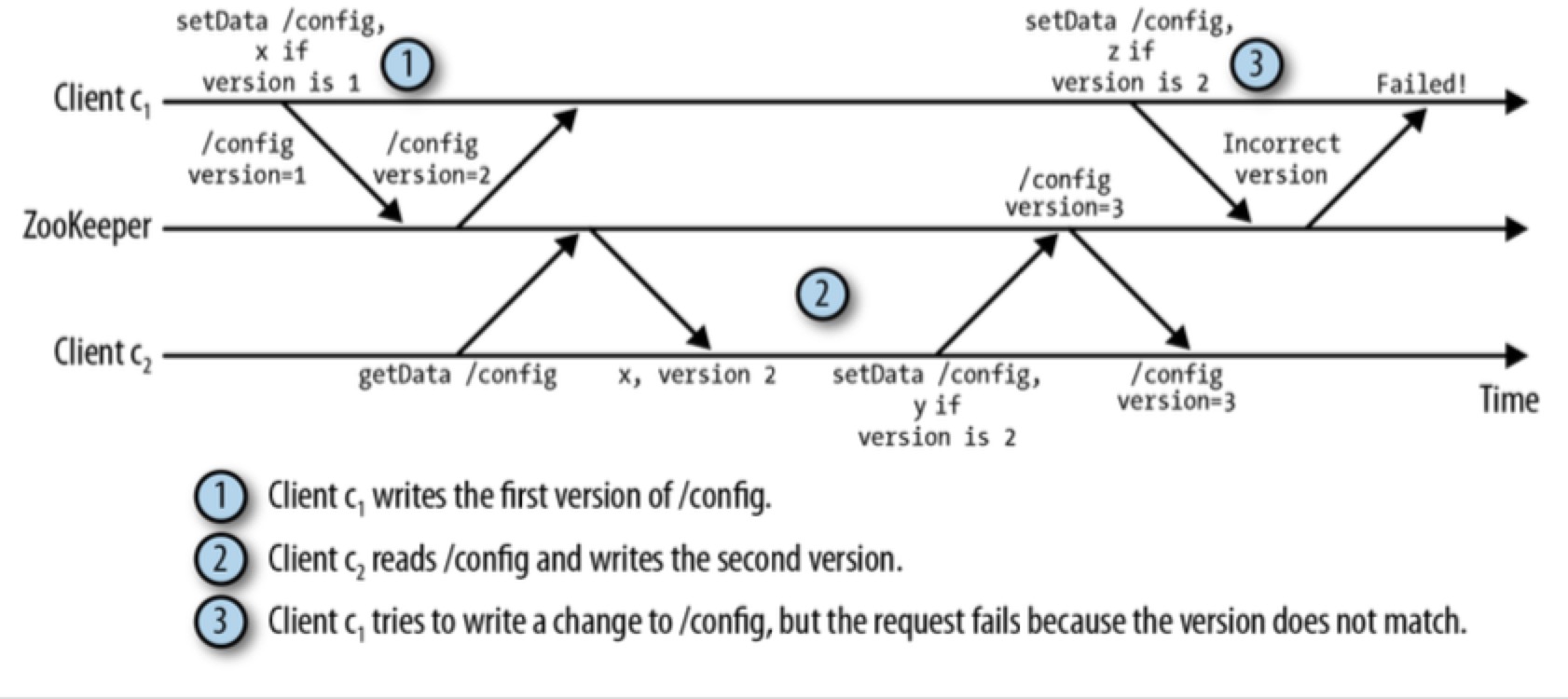 SetData, delete 是有条件执行 的 api。client 执行 setData, delete 操作时,会把自身所有的 version 传过来,如果这个 version 和 zk server 上的 version 相等,才能执行该操作。
SetData, delete 是有条件执行 的 api。client 执行 setData, delete 操作时,会把自身所有的 version 传过来,如果这个 version 和 zk server 上的 version 相等,才能执行该操作。
通过 version 来有条件的修改数据,是乐观锁的思想
MaxBuffer
该参数控制了 znode 的大小限制,默认是 1MB。不建议修改该值,因为 ZooKeeper 本身并不适合作为大规模数据存储使用。
Multiop
Multiop 可以原子性地执行多个 ZooKeeper 的操作,即在 multiop 代码块中的所有操作要不全部成功,要不全部失败。
ZooKeeper Quorums
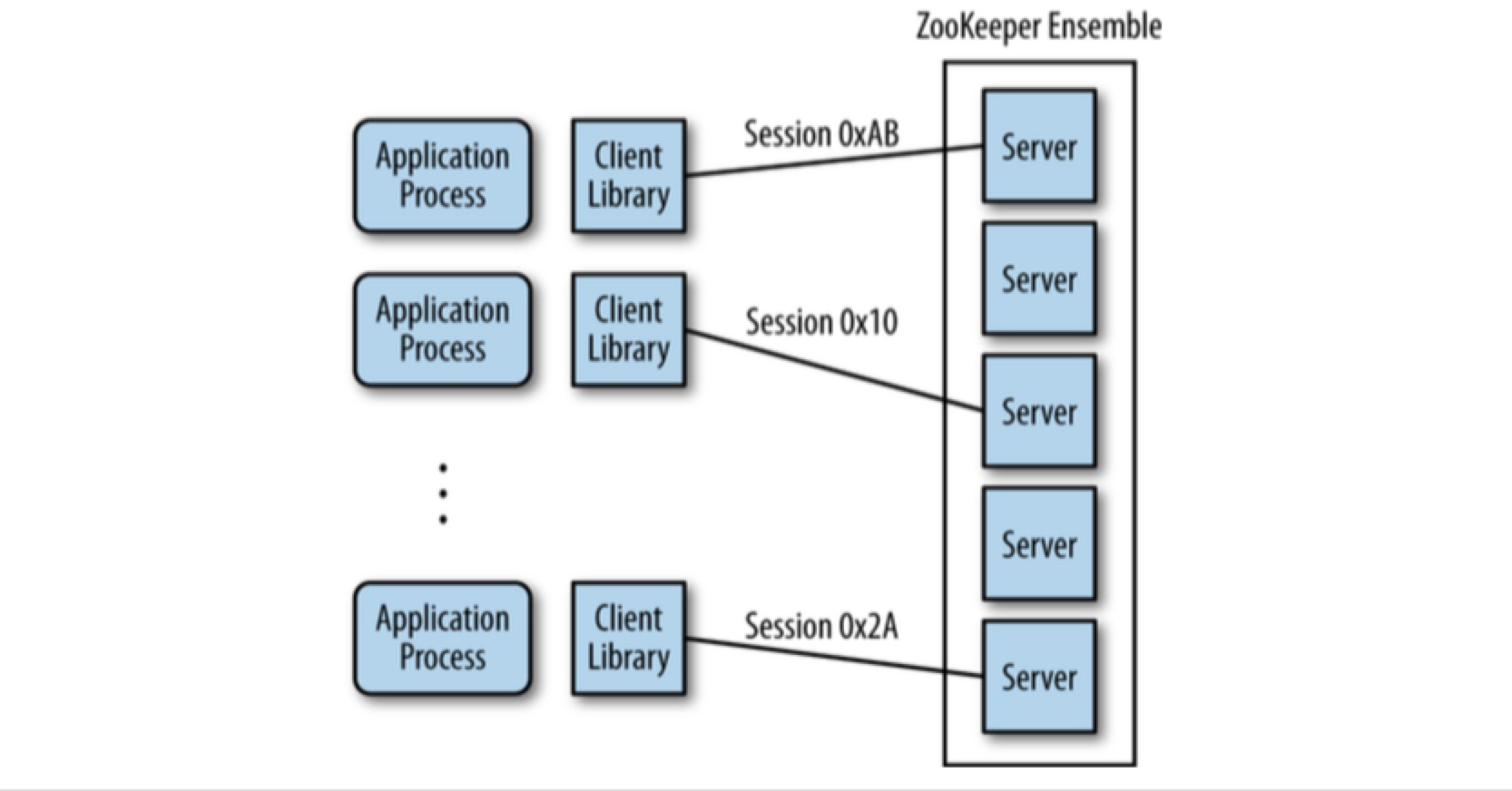 我们和 zk 交互时,一般都是通过 zk 提供的 client 来和 zk server 通信。
我们和 zk 交互时,一般都是通过 zk 提供的 client 来和 zk server 通信。
zk 可以运行在两种模式下:
- standalone: 单机
- quorum: 集群
quorum 可以翻译为:仲裁/法定人数
quorum mode 下的 zk 又叫做 ZooKeeper ensemble,server 内部进行状态数据的同步。 集群模式下,选择一个服务器做为 leader,其他服务器追随 leader,被称为 follower。
leader:
- leader 处理所有的写请求(create, delete, setData)
follower:
- followers 只能同步 leader 发出的写操作更新,不能直接执行 client 的写请求
- followers 只能处理 client 发起的读请求(exists, getData, getChildren)
Observers
除了 leader & follower 外,zk 中还存在一种 server:observer。观察者不会参与决策哪些请求可被接受的过程,只是观察决策的结果。
| follower | observer | |
|---|---|---|
| leader election | true | false |
| forward write request | true | true |
| leader message | leader分阶段给follower发两条: proposal+commit(zxid) | 在transaction committed后,leader一次性给observer发一条 inform(proposal + commit zxid) |
followers 和 observers,这两种服务器也都被称为学习者。
引入 observer 的一个主要原因是提高读请求的可扩展性。follower 是可以提高读效率,但是它是需要参与写操作的投票的,越多的 followers 需要越多的 quorum 来决策,会导致越慢的写性能。通过加入多个 observers,可以在不牺牲写操作的吞吐率的前提下服务更多的读操作。 当然,增加 observer 也不是完全没有开销的。每一个新加入的 observer 将对应于每一个已提交事务点引入的一条额外消息。然而,这个开销相对于增加参与投票的 followers 来说小很多。
配置 ZooKeeper 集群使用观察者,需要在观察者服务器的配置文件中添加以下行:peerType=observer 同时,还需要在所有服务器的配置文件中添加该服务器的:server.1:localhost:2181:3181:observer
Quorum
quorum 有两个作用:
- zk cluster 正常运行所需的最少 server 数。在这里理解为参与投票的最少可用法定人数。
- server 在返回 client success 前,最少写成功的 servers 数,同步 & 异步的结合。这种意义上来说,和 kafka 中的 acks 是一个概念。
需要注意,observers 是不可以作为 quorum 的。举个例子: zk cluster = 1 leader + 4 followers + 4 observers. quorum = 3
假设集群个数设置为 2*n+1,quorum 的选择很关键,它需要保证在 cluster 正常的情况下(至少 quorum 正常),写入成功的数据不会丢失。 建议 quorum >= n+1:
- 保证至少有 quorum 个 servers 运行:防止脑裂 split-brain
- 保证至少有 quorum 个 servers 保存成功数据:当少于 n+1 个 servers crash / network partition 时,至少还有一台机器存有最新数据
quorum 控制集群模式下,数据一致性的强弱。
Cluster 中 server 的配置
在 quorum 模式下,zk cluster 会有多个 servers,每个 server 都有自己的配置文件,该文件中需要设置 cluster 中其他 server 的信息: server.1=127.0.0.1:2222:2223 server.2=127.0.0.1:3333:3334 server.3=127.0.0.1:4444:4445
第二个 port 用于 quorum communication,第三个 port 用于 leader election。
客户端随机连接到 zk servers 中的一台服务器。这样可以针对 ZooKeeper 做一个简单的负载均衡。不过,客户端无法指定优先选择的服务器来进行连接。如果有优先级的业务需求,可以在给 client 配置 server list 时,只配置优先的地址。当然了,如果这个优先地址的 server 宕掉,client 也能正常的连接到别的未配置在 client 本地 property 中的地址。
Requests, Transactions, and Identifiers
leader 将每一个写请求转换为一个事务(transaction)。事务包含:
- 要修改的路径
- 修改的值
- 新的版本号
- 分配的 ZooKeeper transaction ID(zxid)
事务的特点:
- 一个事务为一个单位,也就是说所有的变更处理需要以原子方式执行。
- 事务还具有幂等性,我们可以对同一个事务执行两次,得到的结果是一样的,甚至还可以对多个事务执行多次,同样也会得到一样的结果,前提是我们确保多个事务的执行顺序每次都是一样的。事务的幂等性可以让我们在进行恢复处理时更加简单。
- 只有改变 ZooKeeper 状态的操作才会产生事务,对于读操作并不会产生任何事务。
zxid 为一个64位 long 整数,分为两部分,每个部分32位:
- 时间戳(epoch)
- 计数器(counter)
epoch 代表了管理权随时间的变化情况,epoch 的值在每次进行 leader election 时增加,一个 epoch 表示某个服务器行使管理权的这段时间。在一个 epoch 内,leader 根据 counter 定义每一个 transaction。zxid 可以很容易地与 transaction 被创建 epoch 相关联。
![]()
综合来看,zxid 有两个主要作用:
- 通过 zxid 对事务标识,就可以按照 leader 指定的顺序在各个服务器中顺序执行
- 服务器之间在进行新的 leader election 时交换 zxid 信息,哪个无故障服务器接收了更多的事务,就选举那个作为新的 leader
ZAB: Broadcasting State Updates
Zookeeper 是通过 ZAB(ZooKeeper Atomic Broadcast protocol) 实现
- leader election
- data replication consistency
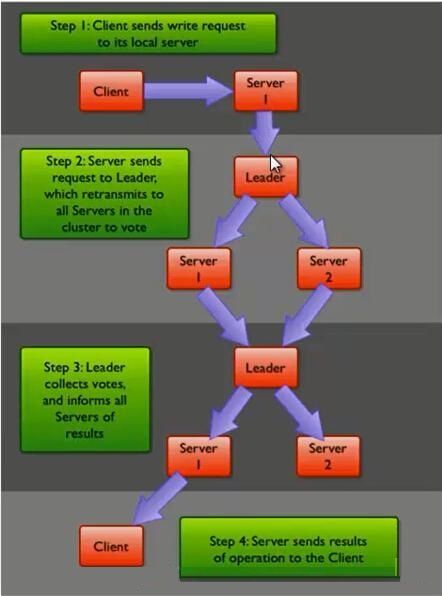
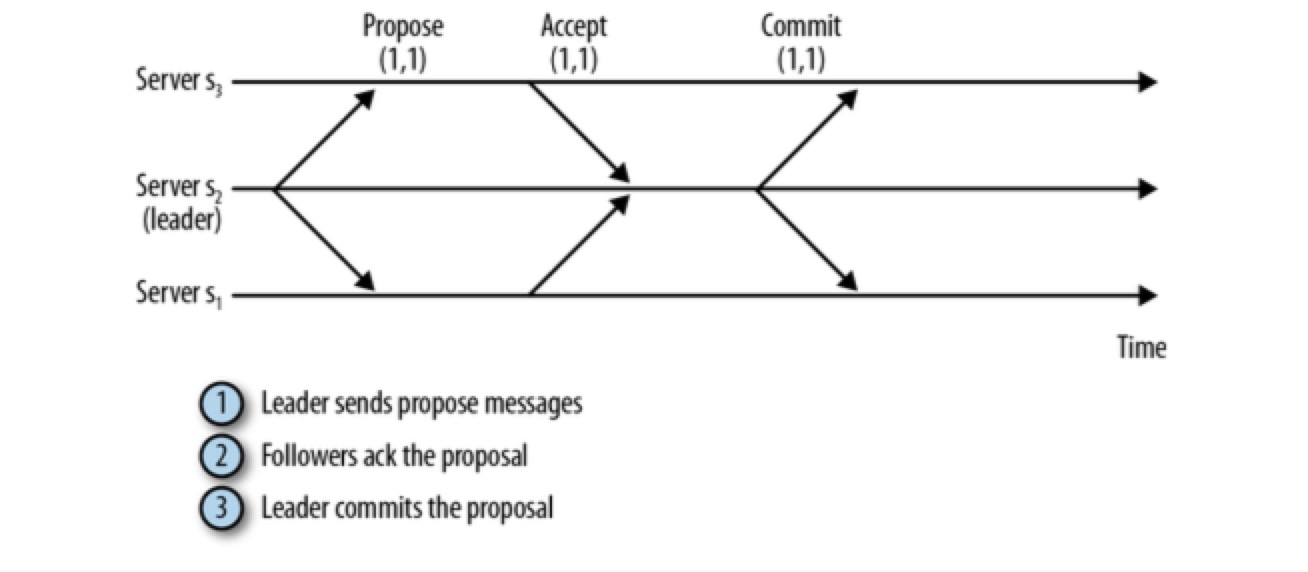
Zookeeper 通过 ZAB 协议来进行 transaction commit 操作,ZAB 协议和 2PC 有相似之处:
- 接到 client 的写请求后,follower 将请求转发给 leader
- leader 向所有 followers 发送一个 proposal 消息,该消息中包含写事务
- 当一个 follower 接收到 PROPOSAL 后,会响应 leader 一个 ACK 消息,通知 leader 其已接受该提案(proposal)
- 当quorum个以上服务器发送的 ack 后(该仲裁数包括 leader 自己),leader 就会给整个集群发 commit 消息
- 之后 leader 响应 client success,数据才算写入成功
最终一致性
可以看到,ZAB 协议由于只要求 quorum 的 followers 发回 ack 消息,就会在集群间 commit。由于网络/服务器性能,提交并非在所有 servers 间实时完成,意味着可能有 client 连接的 server 读不到最新的数据,所以我理解,Zookeeper 是最终一致性系统。
强一致性
从 client 角度如果想保持强一致、读到的数据是最新的话,可以在读取前 sync 一下,这会使 client 连接的 server 从 master 同步最新的数据,那么之后读的就是最新的。
单调一致性
即使 client 不调用 sync,zk 也为 client 保证了单调性,即 client 不会读到比之前自己读到的数据还旧的数据,这主要是发生在 client 重连 server 时。zk 保证 client 不能连接到比自身已发现的 zxid 还旧的 server 上。因此,如果一个 client 在位置 i 观察到一个更新,它就不能连接到只观察到 i’<i 的 server 上。
ZAB 保证
- 事务在服务器之间的传送顺序的一致
- 服务器不会跳过任何事务
- 一个被选举的 leader 确保在提交完所有之前的 epoch 内需要提交的 transactions,之后才开始广播新的 transaction。
zk 和 kafka 不同: kafka 写数据时,通过 acks 可以控制返回 producer success 时,最少写功能数。但是对于读,kafka consumer 只能读取被全部 replicas 同步完成的数据。 zk 写数据时,只要求 quorum success 就可以,这和 kafka 还比较像。但是对于读,zk client 可能读到只被部分 sync 的数据,同样,可能连接的 zk server 还没有 sync 该数据,导致 client 读不到
Leader Elections
zk 可通过临时节点为别的 master-slave 架构的分布式集群提供 leader election,如 Kafka,但是 zk cluster 如何进行自身集群 leader 的选举呢?
- 每个服务器启动后进入 LOOKING 状态,开始选举一个新的 leader 或查找已经存在的 leader
- 如果 leader 已经存在,其他服务器会通知这个新启动的服务器,告知哪个服务器是 leader ,与此同时,新的服务器会与 leader 建立连接,以确保自己的状态与 leader 一致。
- 如果集群中所有的服务器均处于 LOOKING 状态,这些服务器之间发送 leader election notifications 来选举一个 leader。 notification 包括该服务器的投票(vote)信息,投票中包含服务器标识符(sid)和最近执行的事务的 zxid 信息,比如,一个服务器所发送的投票信息为(1,5),表示该服务器的sid为1,最近执行的事务的 zxid 为 5。拥有最近一次的 zxid & 被 quorum 的 nodes 同意的服务器将赢得选举。
- 选举中胜出的服务器将进入 LEADING 状态,而集群中其他服务器将进入 FOLLOWING 状态。
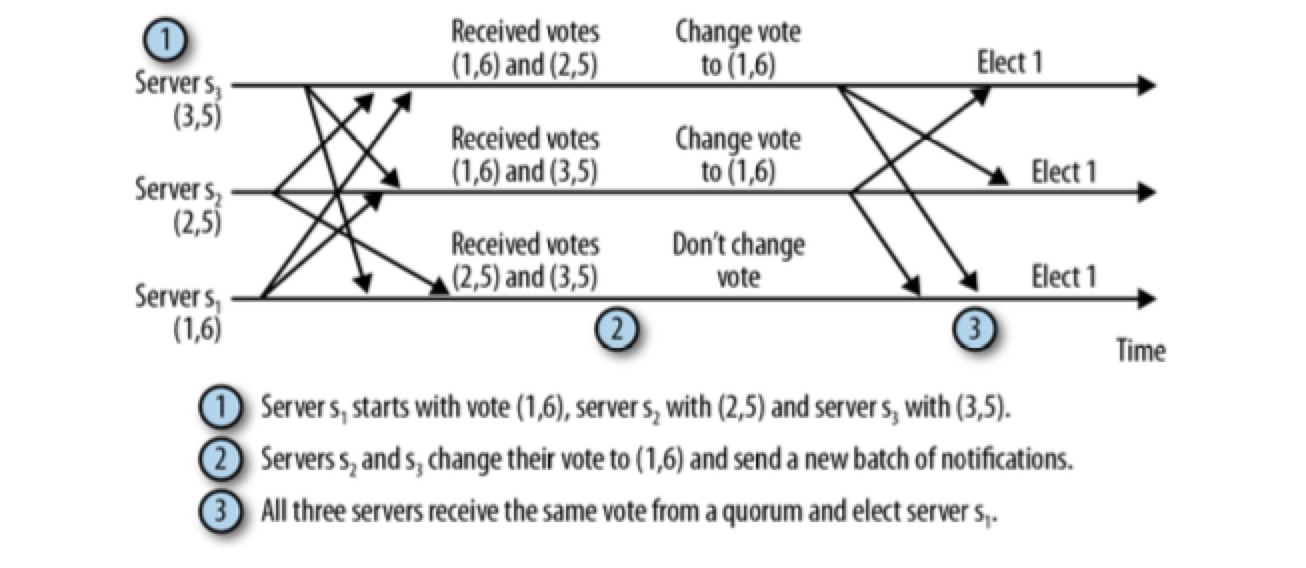
上图是 leader election 的理想情况,考虑下图:
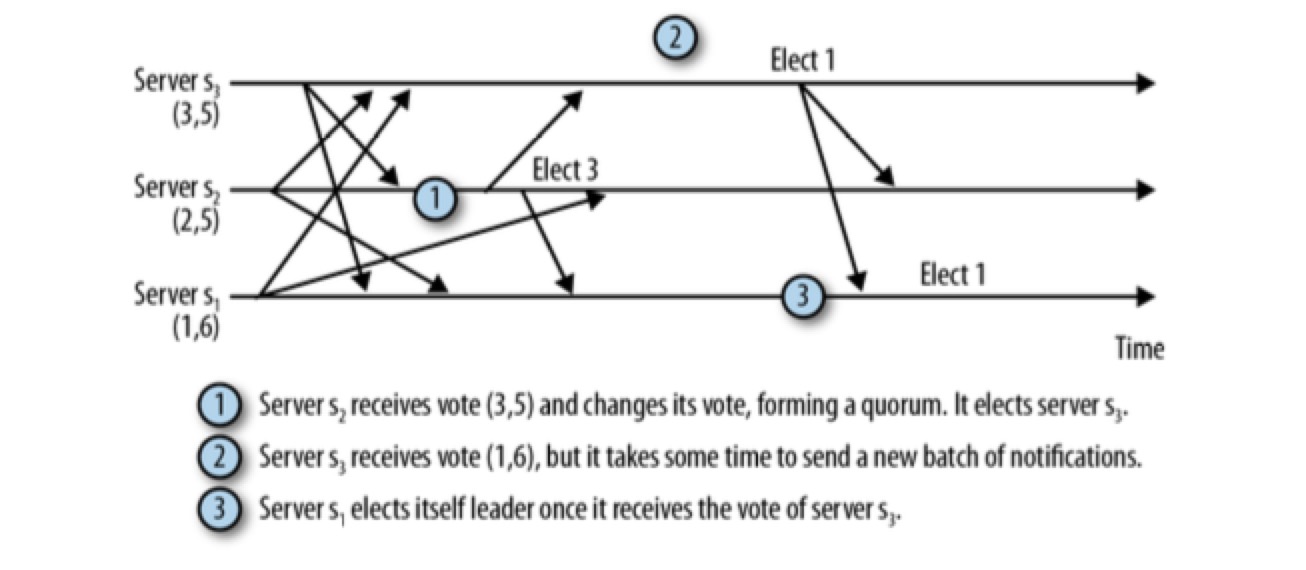 在从服务器 s1 向服务器 s2 传送消息时发生了网络故障导致长时间延迟,与此同时,服务器 s2 选择了服务器 s3 作为 leader ,最终,服务器 s1 和服务器 s3 组成了仲裁数量(quorum),并将忽略服务器 s2。
在从服务器 s1 向服务器 s2 传送消息时发生了网络故障导致长时间延迟,与此同时,服务器 s2 选择了服务器 s3 作为 leader ,最终,服务器 s1 和服务器 s3 组成了仲裁数量(quorum),并将忽略服务器 s2。
如果让 s2 在进行 leader 选举时多等待一会,它就能做出正确的判断。如下图:
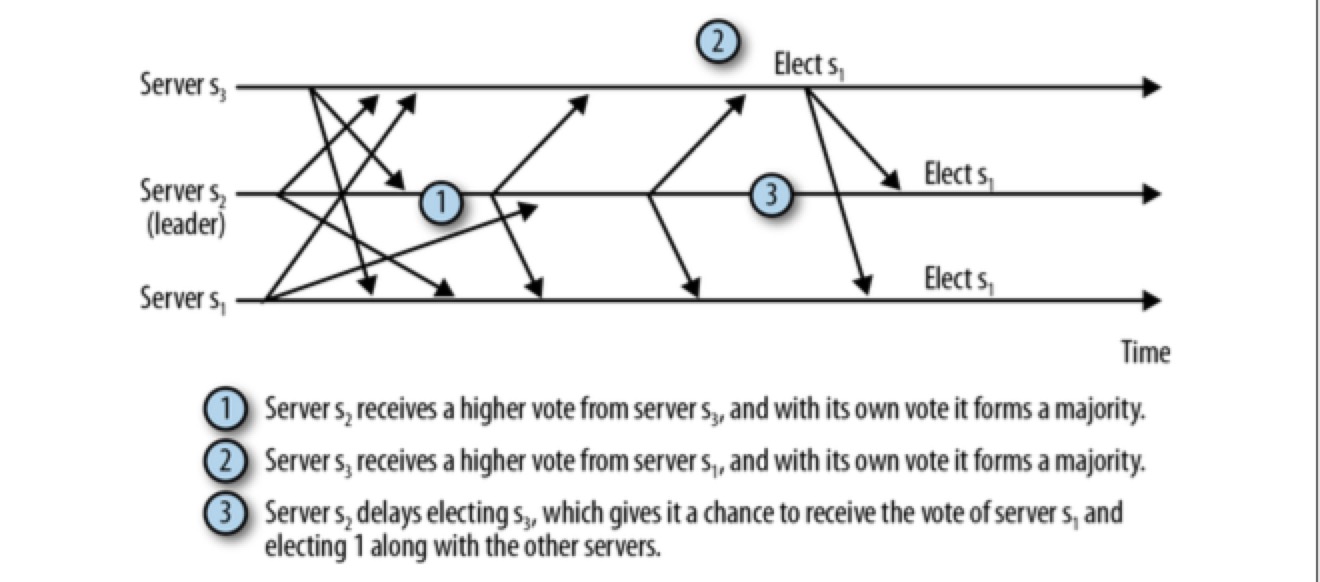 但是很难确定服务器需要等待多长时间,在现在的实现中,默认的 leader 选举使用固定值 200ms,但与恢复时间相比还不够长。如果由于各种原因导致一轮选举无法选出 leader,就需要进行另一轮的 leader 选举。
但是很难确定服务器需要等待多长时间,在现在的实现中,默认的 leader 选举使用固定值 200ms,但与恢复时间相比还不够长。如果由于各种原因导致一轮选举无法选出 leader,就需要进行另一轮的 leader 选举。
一个 zk 服务器必须被至少 quorum 数量的服务器所认可,才能被选为 leader,以避免 split brain(这种情况将导致整个系统状态的不一致性,最终客户端也将根据其连接的服务器而获得不同的结果)。如果在 leader election 时无法达到仲裁法定数量,ZooKeeper cluster 也将无法正常服务。
Cluster Configuration
担任 leader 的 zk server 需要做很多工作,它需要与所有 followers 进行通信并会执行所有的变更操作,也就意味着 leader 的负载会比 followers 的负载高,如果 leader 过载,整个系统可能都会受到影响。可以配置 zookeeper.leaderServes=no,使 leader 除去服务 client 连接的负担,使 leader 将所有资源用于处理 followers 发送给它的变更请求,这样可以提高系统写操作的吞吐能力。但如果 leader 不处理任何与其直连的客户端,followers 就需要承担有更多的客户端,当集群中 servers 比较少的时候,followers 压力也会比较大,这也是需要权衡的。默认情况下,leaderServes的值为“yes”。
Sessions
会话(Session)是 zk 的一个重要的抽象。在对 zks server 执行任何操作前,zk client 需要先和 server 建立 session。当 session 由于任何原因关闭时,ephemeral nodes 都将被 zk 删除。
保证请求有序、临时 znode 节点删除、watch 都与 session 密切相关。
在 Java 中,当 new Zookeeper() 时,就创建了一个 session。zk client 通过 TCP 协议和 zk server 通信。zk client 连接到 server 后,后台就会有一个线程来维护这个 session。正常情况下不需要开发人员维护与 zk 的连接,zk client 会监控与 zk server 之间的连接,客户端库不仅告诉我们连接发生问题,还会主动尝试重新建立通信。一般客户端开发库会很快重建会话,以便最小化对应用的影响。所以不要关闭会话后再启动一个新的会话,这样会增加系统负载,并导致更长时间的中断。
session 提供了 order guarantees,这里需要注意:
- one client 使用 single session 时,可以保证消息的 order,即 FIFO。
- one client 使用 multiple sessions 时,不保证 cross sessions 间的 order。
States and the Lifetime of a Session
Session 的生命周期是指 session 从创建到结束(不管是优雅的关闭/timeout 导致的过期)的过程。Session 状态分为:CONNECTING, CONNECTED, CLOSED, and NOT_CONNECTED.
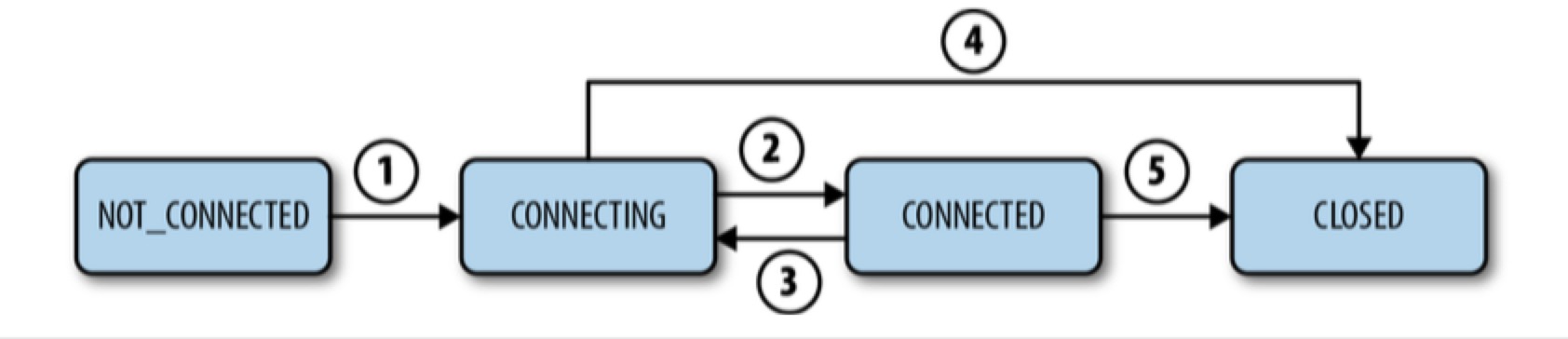
当 client 丢失和当前 zk server 的连接或者无法接到 server 的响应时,session 会切换回 CONNECTING 状态,并尝试重连另外一个 zk server。
- 如果 client 能尽快连到一个新的 server 或者重连到旧的 server,并且 server 确认 session 有效后,session 切换回 CONNECTED 状态。
- 如果 client 较长时间未能联系上 server,server 会认为 session expired
- 如果 client 一直联系不上 server,client 会一直处于 connecting 状态,直到 client 显示关闭 session
- 如果最终 client 联系上了 server,server 会告知 client session expired & closed
zk 中只有 server 才能判定 session expired,但是 client 可以选择主动 close session
Session timeout
所以在创建 session 时,要合理的设置 timeout,这个参数设置了 zk server 允许 session 被声明为 expired 前存在的时间。
- server: 如果经过 timeout 时间后,server 还未收到这个 session 的任何消息,server 就会认为该 session expired。
- client: 在 1/3 of timeout 时,未从 server 收到任何消息,它会向该 server 发送 heartbeat。在 2/3 of timeout 后,client 开始从 server list 中寻找满足要求(这个 server 的状态要最少与 client 最后连接的 server 的状态一样)的 zk server,此时留给它 1/3 of timeout 去寻找。
Servers and Sessions
在独立模式下,单个 zk server 会跟踪所有的 session,而在仲裁模式下则由 leader 来跟踪和维护,followers 仅仅是把 client 连接的 session 转发给 leader。为了保证 session 的存活,client 需要定期发送 heartbeat 到 zk server。server 收到 heartbeat 后,通过更新 session 的 expiration time 来触发 session 活跃。 在仲裁模式下,leader 每半个 tick 发送一个 PING 消息给它的 followers,followers 返回自从最新一次 PING 消息之后的一个 session 列表。
Watches and Notifications
对于 znode 来说,它可能被创建、添加 data、修改 data、增加子节点、删除。client 可能需要及时获取到这些改变:
- pull mode: client 对改变敏感,为了保证及时获取到更新,需要非常频繁的 poll,但是 changes 毕竟不高频,poll 会浪费大量的资源
- notification mode / push mode: client 向 zk 注册需要接受通知的 znode,通过对 znode 设置 watch 来实现
一个 watch(监视点)由以下元素组成:
- znode
- event
具体可分为:
- data watches
- create a znode event
- delete a znode event
- set the data of a znode event
- child watches
- changes to the children of a znode event
NodeCreated: 通过 exists 调用设置一个监视点。 NodeDeleted: 通过 exists 或 getData 调用设置监视点。 NodeDataChanged: 通过 exists 或 getData 调用设置监视点。 NodeChildrenChanged: 通过 getChildren 调用设置监视点,这种 watch 只有在 znode 子节点创建或删除时才被触发。
当一个 watch 被一个 event 触发时,就会产生一个 notification。客户端会以 callback function 的形式收到 notification,并根据自己的业务逻辑实现一个 watcher 来处理收到的 notification。
ZooKeeper as a Message Queue。Watch/Notification 机制某种程度上可以理解为 Message Queue:
- kafka 中 consumer 关注一个 topic,topic 中有消息时,kafka broker 发 message 给 consumer
- zk client 对 znode 添加 watch,当 znode 有改动,zk server 发 notification 给 client
One-shot operation
Watch(监视点)是 One-shot operation,即 watch 只被触发一次,发送一个 notification。为了接受多次通知,client 需要在每次收到 notification 后,注册一个新的 watch。收到 notification <–> 注册新 watch 中间,znode 可能又发生了改变。set watch 前,会自动再 read 一次,所以不会丢消息。
客户端设置的每个 watch 与 session 关联
- 如果 session expired / close,等待中的 watch 将会被删除
- 如果 session 没有 expired / close,而是 connecting,watch 就可以跨越不同 server 的连接而保持。例如,当一个 client 与一个 ZooKeeper server 的连接断开后连接到 zk cluster 中的另一个 server,client 会发送未触发的 watch list,在新 server 注册 watch 时,server 将检查被 watch 的 znode 节点在之前注册 watch 之后是否已经变化,如果已发生变化,一个 notification 就会被发送给 client,否则在新的 server 上注册 watch。
Usage scenario
watch 的使用场景非常广泛,下面仅举例说明:
- master-slaves 架构中的 master election
- distributed lock
- 分布式应用服务中 server-a 和 server-b 之间的调用,server-b 多机部署,server-b 的 address infos 可以存在 zk 中,sever-a 从 zk 拿到 server-b 的信息 & cache 到本地,并且 set watch,当 server-b list 变化时,实时更新 cache。这种场景即是把 zk 当成注册中心。
Servers and Watches
监视点只会保存在 server 的内存中,而不会持久化到硬盘。当 client 与 zk server 的连接断开时,它的所有监视点会从 server 的内存中清除。因为 client 库也会维护一份监视点的数据,在重连之后监视点数据会再次被同步到 zk server。
Ordering Guarantees
Order of Writes
zk cluster 保证使用相同的顺序执行状态的更新。例如,如果一个 ZooKeeper server 执行了先建立一个 /z 节点的状态变化之后再删除 /z 节点的状态变化这个顺序的操作,所有的在 zk cluster 中的 server 均需以相同的顺序执行这些变化,注意:这里的相同顺序并不强制是同步实时。
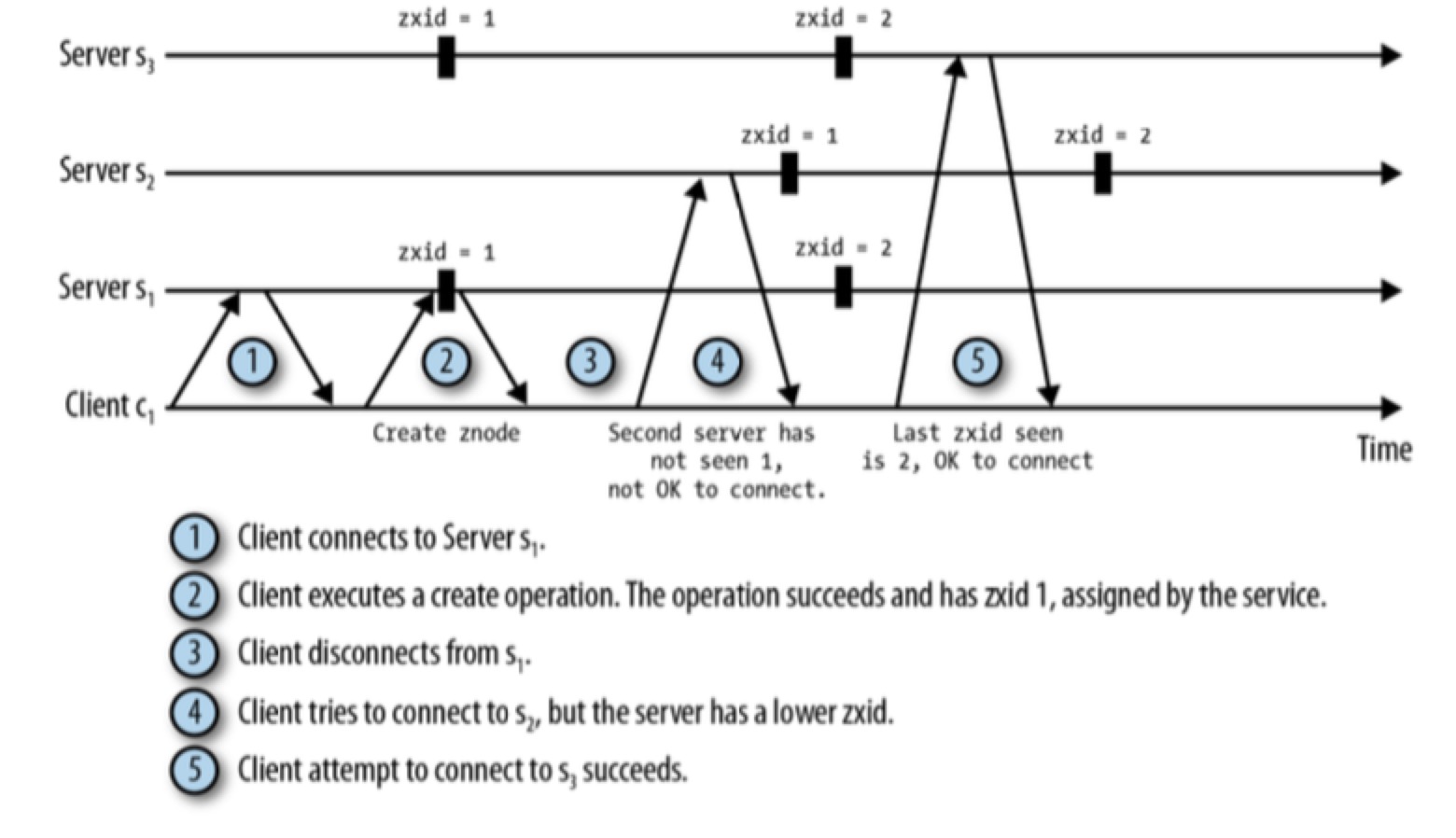
Order of Reads
ZooKeeper client 可能是在不同时间观察到了更新,但是总会以相同的顺序观察到更新,即使它们连接到不同的 server 上,这是一种最终一致性的实现。
考虑下图情况:
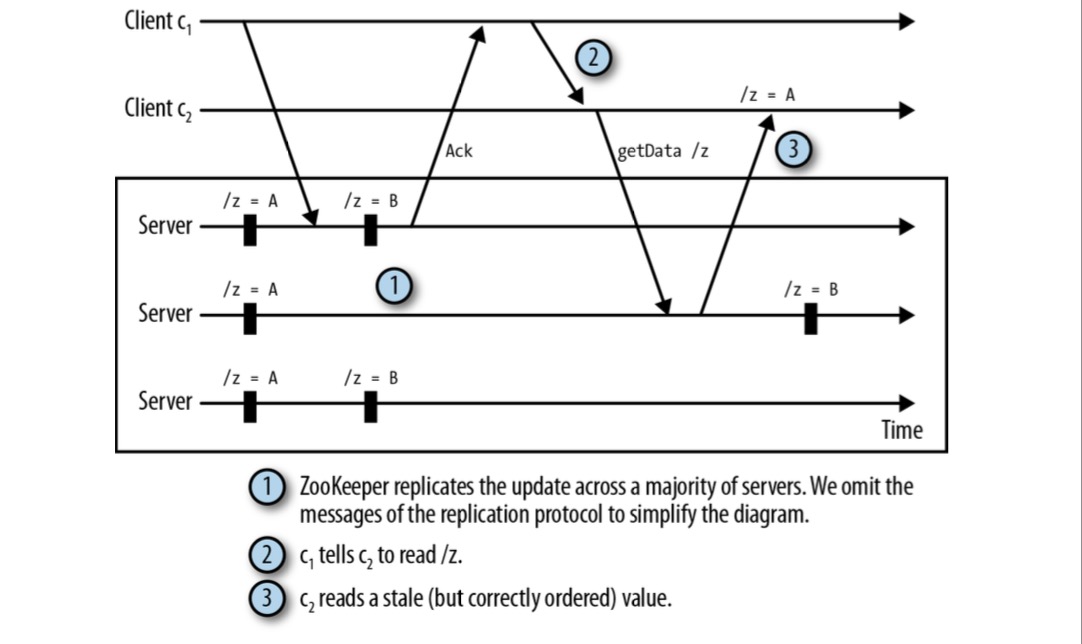 c2 未能成功读到 /z=B 的数据是因为这个 notification 不是由它连接的 server 发送的,而是 c1 通过 hidden channel(非 zk)通知的,这时 c2 getData 时,它连接的 server 暂时还未同步到 /z=B,导致获取失败。
Zookeeper 中针对这种隐蔽通道(hidden channel)可能获取不到最新数据的情况提供了方法:sync。
c2 未能成功读到 /z=B 的数据是因为这个 notification 不是由它连接的 server 发送的,而是 c1 通过 hidden channel(非 zk)通知的,这时 c2 getData 时,它连接的 server 暂时还未同步到 /z=B,导致获取失败。
Zookeeper 中针对这种隐蔽通道(hidden channel)可能获取不到最新数据的情况提供了方法:sync。
client 向 server-1 发起 getData 前先调用 sync。当 server-1 收到 sync 调用时,会刷新 zk leader server 与 server-1 之间的通道,刷新的意思就是说在调用 getData 的返回数据的时候,server-1 确保返回所有 client 调用 sync 方法时所有可能的变化情况。
突然想起来 kafka 中的实现,kafka 其实是实现了强一致性的,虽然 replication 是异步的,但是 consumers 消费时只能获取到写入所有 replicas 的 msg(kafka consumer 只从 leader 读取 msg),不像 zk client 连接任意 server 读取数据。
Dealing with Failure
故障发生的主要点有三个:ZooKeeper server、network、Zookeeper client。故障恢复取决于所找到的故障发生的具体位置。
Recoverable Failures
遇到可恢复的故障,ZooKeeper client 库会积极地尝试重连另一个 ZooKeeper server,直到最终重新建立了 session。一旦 session 重新建立,ZooKeeper 会产生一个 SyncConnected 事件,并开始处理请求。ZooKeeper 还会注册之前已经注册过的 watch,并会对失去连接这段时间发生的变更产生监视点事件。
ConnectionLossException 异常为 recoverable failure
如果在连接丢失时,客户端没有进行中的请求,这种情况只会对客户端产生很小的影响。但是,如果存在进行中的请求,连接丢失就会产生很大的影响。考虑下图场景:
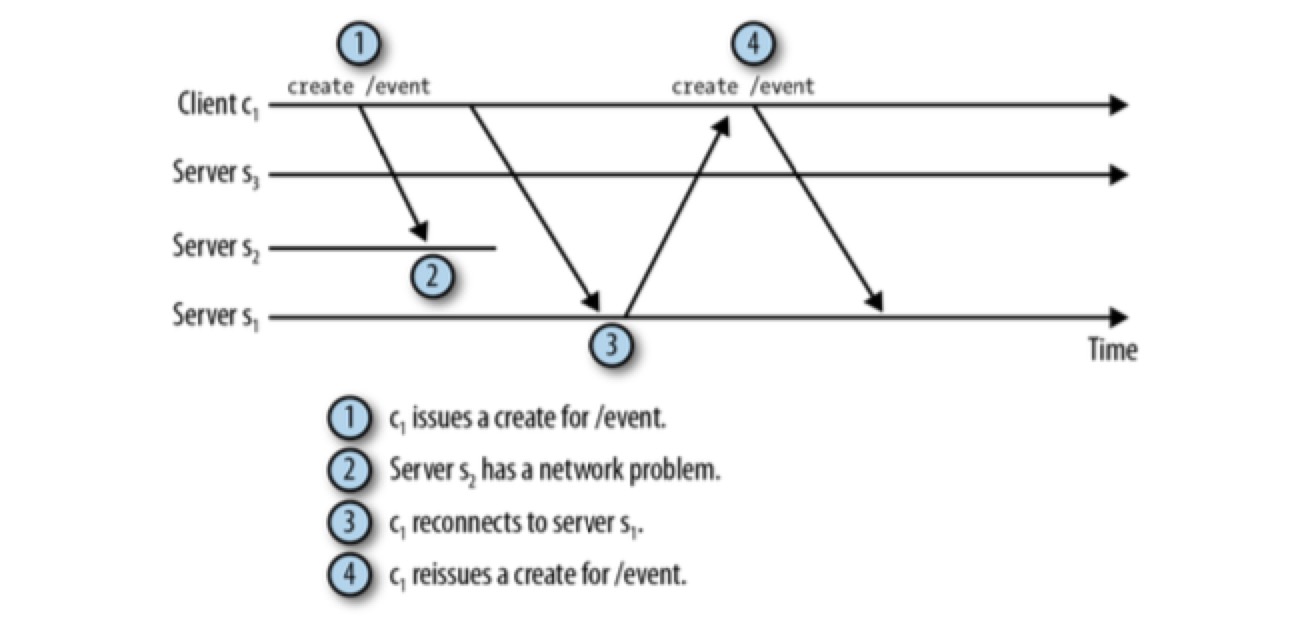 当接收到 ConnectionLossException 异常时, 客户端无法判断请求是否已经被处理,处理连接丢失会使我们的代码复杂,因为应用程序必须判断请求是否已经完成。
当接收到 ConnectionLossException 异常时, 客户端无法判断请求是否已经被处理,处理连接丢失会使我们的代码复杂,因为应用程序必须判断请求是否已经完成。
The Exists Watch and the Disconnected Event
为了使连接断开与重现建立 session 之间更加平滑,ZooKeeper client 库会在新的服务器上重新建立所有已经存在的监视点。当客户端连接 ZooKeeper server,client 会发送 watch list 和最后已知的 zxid(详见之前的介绍),server 会接受这些监视点并检查 znode 节点的修改时间戳与这些监视点是否对应,如果任何已经监视的 znode 节点的修改时间戳晚于最后已知的 zxid,服务器就会触发这个监视点。
然后存在一种错过监视点事件的特殊情况,即通过 exist 注册的监视点:
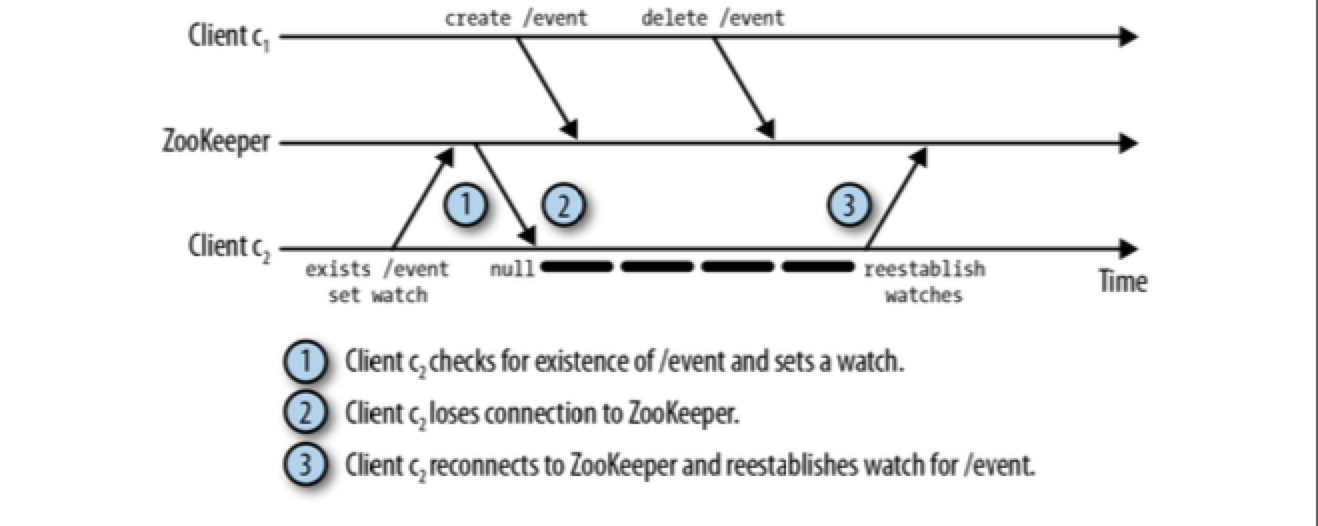
Unrecoverable Failures
有时一些更糟的事情发生,导致 session 无法恢复而必须被关闭。这种情况最常见的原因是:
- session 过期
- 已认证的 session 无法再次与 ZooKeeper 完成认证 这两种情况下,ZooKeeper 都会丢弃 session 的状态。
处理不可恢复故障的最简单方法就是中止进程并重启,这样可以使进程恢复原状,通过一个新的 session 重新初始化自己的状态。如果该进程继续工作,首先必须要清除与旧 session 关联的应用内部的进程状态信息,然后重新初始化新的状态。
故障恢复很复杂 & 容易出现不一致性的问题。ZooKeeper server 无法保护与外部设备的交互操作。
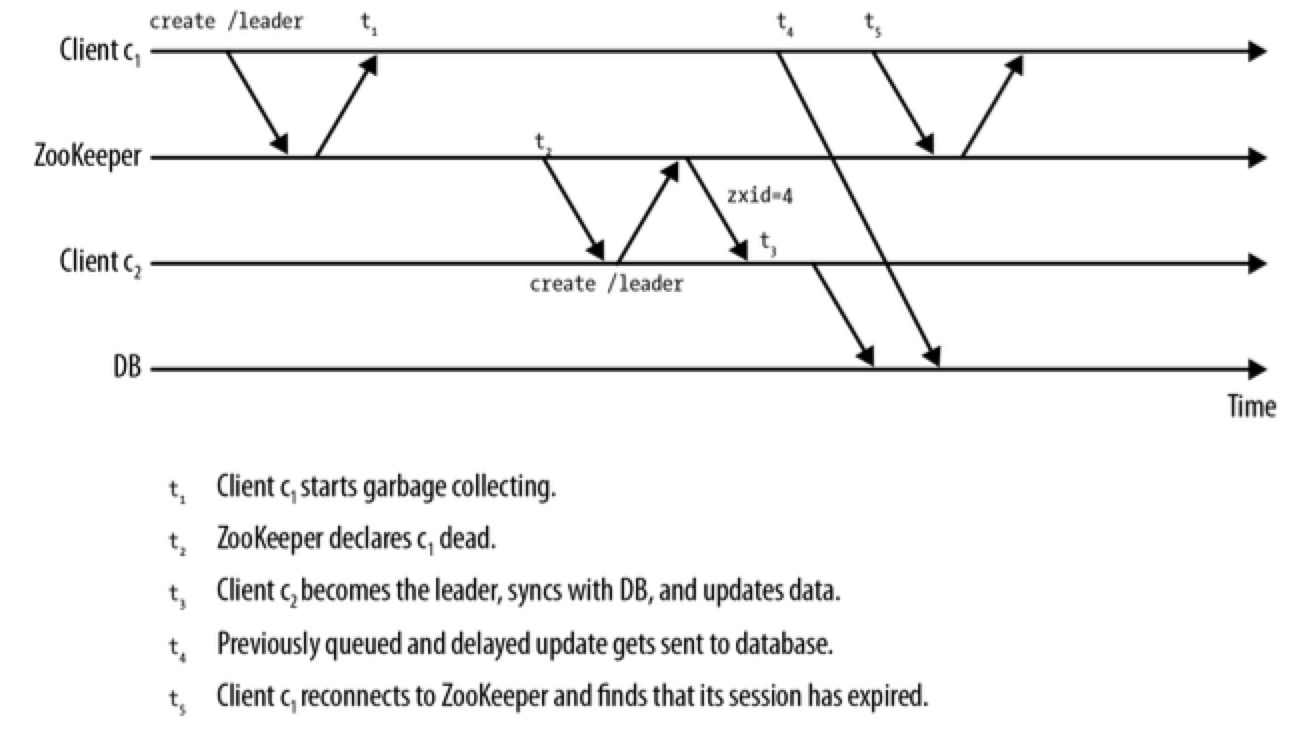
当运行客户端进程的主机发生过载,系统颠簸或因已经超负荷的主机资源的竞争而导致的进程延迟,这些都会影响与 ZooKeeper server 交互的及时性。一方面,ZooKeeper client 无法及时地与 ZooKeeper server 发送心跳信息,导致 client 的 session 超时,另一方面,主机上本地线程的调度会导致不可预知的调度:应用线程认为 session 仍然处于活动状态,并持有主节点,即使 ZooKeeper 线程有机会运行时才会通知 session 已经超时。解决方案如下:
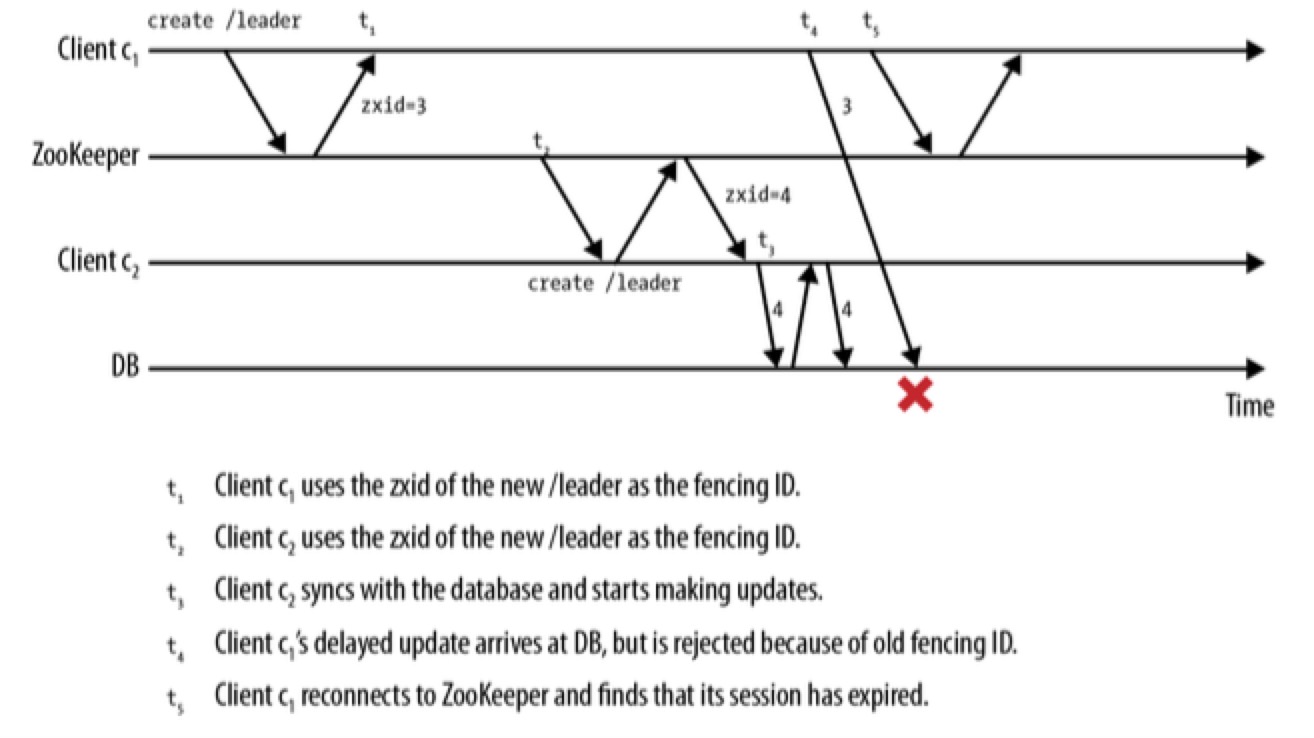 不过,隔离方案需要修改客户端与资源之间的协议,需要在协议中添加 zxid,外部资源也需要持久化保存来跟踪接收到的最新的 zxid。
不过,隔离方案需要修改客户端与资源之间的协议,需要在协议中添加 zxid,外部资源也需要持久化保存来跟踪接收到的最新的 zxid。
时钟偏移也可能导致类似的问题,在 HBase 环境中,因系统超载而导致时钟冻结,有时候,时钟偏移会导致时间变慢甚至落后,使得客户端认为自己还安全地处于超时周期之内,因此仍然具有管理权,尽管其 session 已经被 ZooKeeper server 置为过期。
Locks with ZooKeeper / Mutual exclusion lock / Distributed Lock
我们可以通过 zk 提供的 api 来实现一个 distributed lock。
假设有一个应用由 n 个进程组成,这些进程尝试获取一个锁。为了获得一个锁,每个进程 p 尝试创建 znode,名为/lock。如果进程 p 成功创建了 znode,就表示它获得了锁并可以继续执行其临界区域的代码。一个潜在的问题是进程 p 可能崩溃,导致这个锁永远无法释放。在这种情况下,没有任何其他进程可以再次获得这个锁,整个系统可能因死锁而失灵。为了避免这种情况,可以在创建这个节点时指定 /lock 为临时节点。
其他进程因 znode 存在而创建 /lock 失败。因此,进程监听 /lock 的变化,并在检测到 /lock 删除时再次尝试创建节点来获得锁,如果其他进程又已经创建了,就继续监听节点。
/lock 被删除的原因有多种,即前面提到的 ephemeral node 被 zk 删除的原因
- 当创建该节点的 client 崩溃,或者与 zk 的连接超时
- 当创建该节点的 client 主动关闭 session
// todo: 网络原因导致拿到 lock 的 client 失去连接,别的 client 获得 lock,之前的 client 也以为自己有 lock,造成多个 clients 持有 locks。
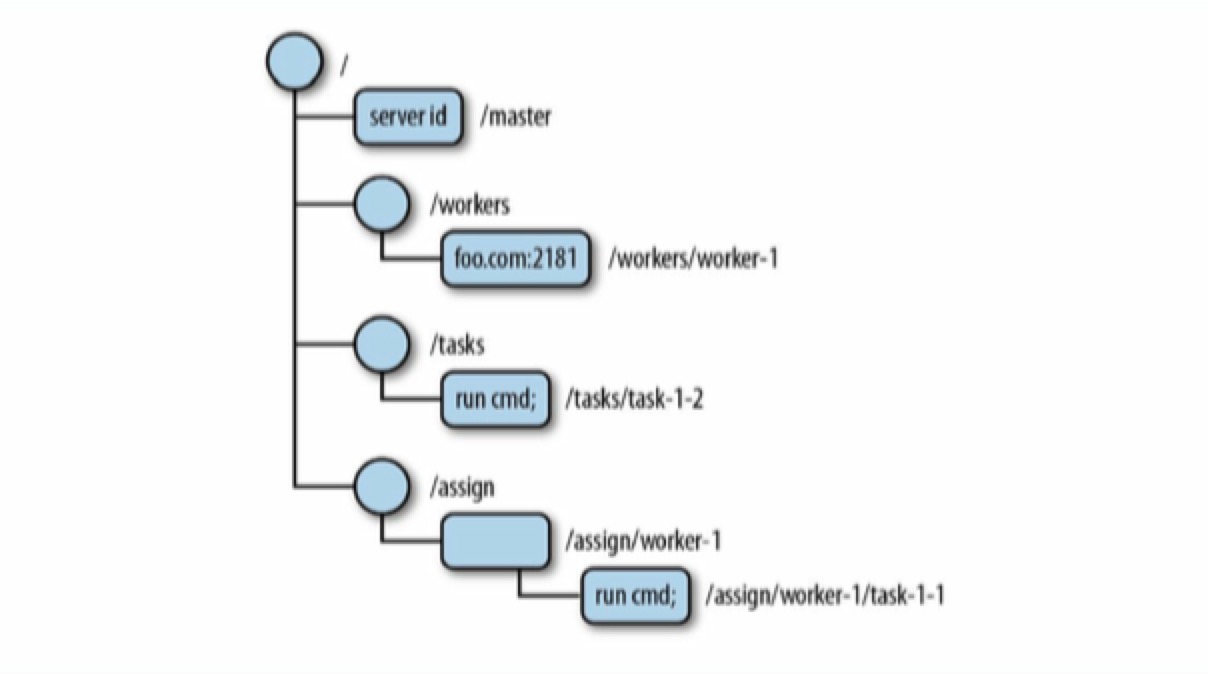
Master-Worker Application design by Zookeeper

分布式系统中非常常见的一种架构是 master/worker (master/slave),包括 Kafka, Es 等都采用该架构。master 负责集群的调度、从节点状态跟踪、任务的分配等(部分应用中 master 也执行任务),worker 执行任务。
master-worker 架构中需要处理的问题包括:
- Master crashes -> master election / leader election
- Worker crashes -> worker crash detection
- Communication failures
- maintaining application metadata: 通过第三方 zk 维护
Leader Election
初识时 client 通过抢占式的创建临时的 /master 节点来推选自己为主节点(我们称为“主节点竞选”)。如果 /master 已存在,client 在 /master 节点上设置一个监视点。 可以在 /master 中添加主机信息,以便 slaves 与 master 通信。此时,master-slaves 集群正常启动。 当 master crash 时,/master znode 自动被删除,同时 zk server 通知所有 slave clients。一旦 slave clients 收到通知,它们就可以开始进行主节点选举,来接管之前 master 的工作。
master election 需要关注两个问题:
- recoverability of the master state
- false suspicion master crash
recoverability of the master state:对于 new master 来说,不仅是直接处理新来的请求,还需要恢复 old master 崩溃时的状态。对于 old master 节点状态的可恢复性,我们不能指望已经 crash 的 old master,这时 zk 就发挥作用了。集群的状态信息可以存储在 zk 中,即使 master 宕机,新的 master 也可以正常接管。
false suspicion master crash:
- 当 master 负载很高,响应缓慢时,可能无法及时的与 zk 发送 heartbeats,导致 zk 以为 master down,从而启动 master election
- network partition 发生,master & 部分 slaves 和 zk 断开网络链接,从而启功 master election,导致系统拆分为两个集群,引发 split-brain
Worker Failures
master 要 watch slaves 创建的临时 /slaves 的状态。如果 slave crash,master 要能及时被 notification 到,并将任务调度到别的 available 的 slaves 上。
Communication Failures
如果某个 slave 和 master 的链接断掉,master 不知道是否需要继续分配这个任务给其他 available slaves:
- 如果分配给新的 slave,旧的 slave 可能已经处理完这个任务,导致重复执行任务
- 如果不分配给新的 slave,旧的 slave 可能没有处理完这个任务,导致任务丢失
这需要根据任务是否可被重复执行来做对应的处理。
这有点像 kafka consumer group 面临的问题。当 consumer 宕机 时,consumer group 并不能确定消息是否成功消费完,所以对于消息不可重复消费的场景, offset 的处理需要格外谨慎。
The Herd Effect and the Scalability of Watches
当 change 发生时,ZooKeeper 会触发这个 znode 节点的变化导致的所有 watch。如果有 1000 个客户端通过 exists 操作监视这个 znode 节点,那么当 znode 节点创建后就会发送 1000 个 notification,因而被监视的 znode 节点的一个变化会产生一个尖峰的通知。这会对性能带来影响。
假设有 n 个客户端争相获取一个锁(例如 /lock)。为了获取锁,一个进程试着创建 /lock 节点,如果 znode 节点存在了,客户端就会监视这个 znode 节点的删除事件。当 /lock 被删除时,所有监视/lock 节点的客户端收到通知。另一个不同的方法,让客户端创建一个有序的节点 /lock/lock-,回忆之前讨论的有序节点,ZooKeeper 在这个 znode 节点上自动添加一个序列号,成为 /lock/lock-xxx,其中 xxx 为序列号。我们可以使用这个序列号来确定哪个客户端获得锁,通过判断 /lock 下的所有创建的子节点的最小序列号。在该方案中,客户端通过 /getChildren方法来获取所有/lock 下的子节点,并判断自己创建的节点是否是最小的序列。如果客户端创建的节点不是最小序列号,就根据序列号确定序列,并在前一个节点上设置监视点。
争夺分布式锁其实和争夺 master 节点非常类似。 distributed lock & leader election 都可以通过 Sequential and ephemeral zNode 来优化 watch/notification 的性能
References